test
暂时写东西的地址:leonlist · 语雀 (yuque.com)
暂时写东西的地址:leonlist · 语雀 (yuque.com)
教材《微型计算机原理与接口技术》
内容主要以8086为主要对象,包括微型计算机的基础知识、8086CPU、寻址方式、指令系统、汇编语言程序设计和存储器。
存储器、运算器、控制器、输入系统、输出系统
二进制B 、十进制D、十六进制H、BCD码
BCD码的每一位数字都用4位二进制来表示,如十进制数(327)对应BCD码(0011 0010 0111)
注意16进制与BCD码的区别:BCD码实质是十进制数,只是采用二进制数对0-9进行编码,所以会出现非法码。
BCD码的加减规则:
数制转换
二、十六进制->十进制
权值相乘,再求累加和
二进制->十六进制
四个一组,每组用等值的十六进制代换
十六进制->二进制
一个十六进制的数,用等值的4个二进制数表示
十进制->二进制
整数:除以2取整,直到商为0,倒排余数
小数:乘以2取整,直到乘积的小数部分为0,顺排整数
带小数:整数、小数分别计算,再合并
数值数据:有符号数、无符号数
非数值数据:字符、图像
需要牢记的ASCII码:
原码、反码、补码
原码:有符号数的,最高位为符号位,正数的符号用0表示,负数用1表示;数值部分为该数的绝对值
+23(17H) 的原码:0001 0111B
-23(-17H) 的原码:1001 0111B
反码:对于有符号数,符号位不变,其他各位取反
补码:对于有符号数,正数不变,负数除了符号位各位取反后加1
注意,补码的补码是原码
-y的补码:对y的补码,所有位全部取反,再加一
有符号n位补码的真值范围 -2^(n-1) — 2^(n-1)-1
无符号数: 0 — 2^n-1
总线:CPU与存储器、I/O端口交换信息的公共通道
I/O接口:CPU和外部设备交换信息的中转站
三大总线:
读:输入 外部->CPU
写:输出 CPU->外部
读内存:存储器取信息->CPU
写内存:信息->存储器
1、存储器分类:
辅助存储器:磁盘、光盘
主存储器:RAM、ROM…
高速缓冲存储器:cache
2、存储器的容量由地址线“宽度”决定
20根地址线,地址范围为:00000H~FFFFFH,1M
位和字节:
位bit:计算机所能表示的最小的、最基本的数据单位
字节byte:由8个位组成
字word:在8086中,由两个字节组成
字长:一次可以直接处理的二进制数码的位数
与通用寄存器的位数、数据总线的宽度有关
寻址能力:CPU能直接存取数据的内存地址的范围
与地址总线的数目有关
主频:时钟频率
MIPS:million instructions per second
总线接口单元BIU(bus interface unit): 主要由段寄存器,地址加法器和指令队列等部件构成
功能: 用于取指令,即负责在CPU内部各部件与存储器、输入/输出接口之间传送数据或指令。
执行单元EU(Execution Unit):主要由通用寄存器组、算术逻辑单元和标志寄存器等部件组成
功能: 用于执行指令,即将已译码指令队列中的内部编码变成按时间顺序排列的一系列控制信息,发向处理器内部有关的部件,以完成指令的执行。
1、只介绍了基本结构寄存器。
2、基本结构寄存器:
8个16位通用寄存器: AX BX CX DX SP BP DI SI
4个16位段寄存器: CS DS ES SS
1个16位标志寄存器:FLAGS
1个16位指令指针:IP
3、功能
AX accumulater 累加器
BX base 基地址指针
CX count 计数寄存器
DX data 数据寄存器
SP stack pointer 堆栈指针
BP base pointer 基址指针
DI destination index 目的变址寄存器
SI source index 源变址寄存器
IP Instruction Pointer 指令指针(用户不能对 IP 进行存取操作,只能由 BIU 自行修改)
其中,SP 、BP、 DI、 SI、 IP 都可以为存储单元提供偏移地址
AH 是 AX 的高8位,而 AL 是 AX 的低8位
4、标志寄存器(又称 程序状态字PSW,16位)
有两类:状态标志,控制标志
状态标志:
控制标志:
指令:单个的CPU操作,通知CPU执行某种操作的“命令”
指令集:所有指令的集合
机器指令:用二进制序列(0、1)代码书写。硬件只能识别、存储和运行机器指令
符号指令:用字符串形式的序列(包含字符串形式的操作码、操作数)
指令的组成: 操作码+操作数
指令长度:机器指令长度为1~16字节
指令地址:多字节指令会占用连续的内存单元,存放指令第一个字节的内存地址
操作数:指令的操作对象(输入数据、输出数据)>可存放于 CPU寄存器、计算机的存储器、接口电路中的端口中
状态标志:
控制标志:
操作数的存在方式(4种):
寻址方式:
立即寻址方式
立即数只能作源操作数,不能作目的操作数
MOV AL, OFFSET BUF
MOV CX, 0A234H( A~F开头的数字,加上0作为前缀)
寄存器寻址方式
操作数包含在寄存器中,由指令指定寄存器的名称
注意:源操作数的长度必须与目的操作数一致,比如不能把AH的内容传送到CX中
MOV AX, BX
INC SI
存储器寻址方式
存储器寻址(内存操作数寻址): 5种
将指令中的逻辑地址(段寄存器名称 : 偏移地址表达式)转化为对应的物理地址,再通过总线系统访问实际的物理存储单元(操作数的物理地址=段基址*16+偏移地址)。
段寄存器名称:存放操作数的存储单元所在的逻辑段:如CS、DS、SS、ES。
16位偏移地址表达式,给出偏移地址,是相对于逻辑段段首单元的地址偏移量
直接寻址方式
物理地址=16*DS+EA,默认为DS为基地址,EA上必须加方括号,与立即数区分
(段超越前缀)ES:[500H],以ES作基地址
ADD AL,DS:[45H] ; 这里段寄存器名称一定要加
MOV AX,ES:[1000H]
MOV AX,DS:BUF 也可以写成 MOV AX,BUF
INC BUF+2
可以用变量名代替数值地址,实际上就是给存储单元起一个名字,变量名在汇编的时候,会给出实际的偏移地址,所以BUF+2,BUF都是直接寻址
寄存器间接寻址方式
源操作数的寄存器的值为操作数的有效地址,寄存器名称外必须加方括号
如果指令中指定的寄存器为BX、SI、DI,段地址为数据段DS
如果为BP,段地址为堆栈段SS
MOV BX,[SI] 物理地址=16*DS+SI
允许段超越前缀
只有一些指定的通用寄存器可作为间址寄存器使用:BX,SI,DI,BP
寄存器相对寻址方式
与寄存器间接寻址类似,就是在有效地址上加一个位移量
MOV BX, COUNT[SI],位移量COUNT 物理地址=16*DS+COUNT+SI
也允许段超越前缀
MOV DH, ES:ARRAY[SI]
基址变址寻址方式
操作数的有效地址为一个基址寄存器(BX或BP)和一个变址寄存器(SI和DI)的内容之和
MOV AX, [BX+SI] 物理地址=16*DS+BX+SI
基址寄存器为BX时,段址寄存器为DS;基址寄存器为BP时,段寄存器为SS
相对基址变址寻址方式
操作数的有效地址为一个基址寄存器(BX或BP)和一个变址寄存器(SI和DI)的内容,再加上指令中指定的8位或16为位移量之和。
就是在基址变址寻址方式上加上位移量
MOV AL,[BX+SI+2]
其他寻址方式
总结一下寻址方式:
MOV 传送指令
IP 寄存器不能用作源操作数或目的操作数
立即数和 CS 寄存器不能用作目的操作数
MOV 指令不能在两个存储单元之间直接传送数据,也不能在两个段寄存器之间直接传送数据
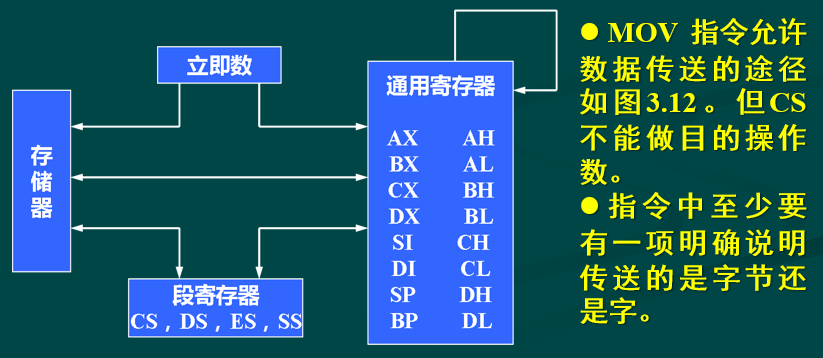
PUSH 进栈指令
PUSH 源 将源操作数推入堆栈,同时栈指针SP值减2
源操作数可以是16位通用寄存器、段寄存器或存储器中的数据字,但不能是立即数
POP 出栈指令
POP 目的 将当前SP所指向的堆栈顶部的一个字送到指定的目的操作数中,同时栈指针SP值加2
源操作数可以是16位通用寄存器、段寄存器或存储单元,但CS不能用作目的操作数
XCHG 交换指令
XCHG 目的, 源 把源操作数和目的操作数相交换
交换可以在寄存器之间、寄存器和存储器之间,但段寄存器不能作为操作数,也不能直接交换两个存储单元之间的内容
XLAT 表转换指令
IN 输入指令
OUT 输出指令
LEA 取有效地址指令
LEA 目的, 源
取源操作数地址的偏移量,并把它传送目的操作数所在单位
源操作数必须是存储单元,而且目的操作数必须是一个除段寄存器之外的16位寄存器
注意与 MOV 指令的区别,MOV 指令传送的一般是源操作数中的内容而不是地址
LDS 将双字指针送到寄存器和DS指令
LDS 目的, 源
从源操作数指定的存储单元中,取出一个变量的4字节地址指针,送进一对目的寄存器
指令中源操作数必须是存储单元,从该存储单元开始的连续4个字节单元 中,存放着一个变量的地址指针。目的操作数必须是16位寄存器,通常使用SI寄存器,但是不能使用段寄存器
LES将双字指针送到寄存器和ES指令
LES 目的, 源
与LDS指令操作基本相同,不同是将源操作数所指向的地址指针中的段地址部分送到ES寄存器中,而不是DS寄存器,目的操作数常用DI寄存器
LAHF 标志送到 AH 指令
把标志寄存器SF、ZF、AF、PF和CF分别传送到AH寄存器位7,6,4,2和0
SAHF AH送标志寄存器
把AH内容存入标志寄存器
PUSHF 标志入栈指令
把整个标志寄存器FLAGS的内容推入堆栈,同时栈指针SP值减2
POPF 标志出栈指令
把当前堆栈指针SP所指的一个字,传送到标志寄存器FLAGS,同时栈指针SP值加2
ADD 加法指令
ADD 目的,源 将源和目的操作数相加,结果送到目的操作数
ADC 带进位的加法指令
ADC 目的,源
在两个操作数相加的同时,还要把进位标志CF的当前值加进去作为和,再把结果送到目的操作数中
INC 增量指令
INC 目的
对目的操作数加一
AAA 加法的ASCII调整指令
DAA 加法的ASCII调整指令
将两个压缩 BCD 数相加后的结果调整为正确的压缩 BCD 数。相加后的结果必须在 AL 中,才能使用 DAA 指令
SUB 减法指令
SUB 目的,源 将目的操作数减去源操作数,结果送到目的操作数
SBB 带借位的减法指令
SBB 目的,源 将目的操作数减去源操作数,还要减去进位/借位标志CF的值,结果送到目的操作数
DEC 减量指令
NEG 取负指令
CMP 比较指令
将目的操作数减去源操作数,但仅将结果反映在标志位上
AAS 减法的ASCII调整指令
DAS 减法的十进制调整指令
MUL 无符号数乘法指令
MUL 源
把源操作数和累加器中的数都当成无符号数,然后将两数相乘,源操作数可以是字节或字
如果源操作数是一个字节,则 AX <- AL * 源
若源操作数是一个字,则 (DX,AX) <- AX * 源
源操作数可以是寄存器或存储单元,不能是立即数
IMUL 整数乘法指令
IMUL 源
把源操作数和累加器中的数,都作为带符号数,进行相乘
AAM 乘法的ASCII调整指令
DIV 无符号数除法指令
DIV 源
对两个无符号二进制数进行除法操作
如果源操作数为字节,16位被除数必须放在AX中,并且有:
AL <- AX / 源(字节)的商
AH <- AX / 源(字节)的余数
(要是被除数只有8位,必须把它放在AL中,并将AH清0,然后相除)
如果源操作数为字,32位被除数必须放在DX、AX中,并且有:
AX <- (DX,AX) / 源(字)的商
DX <- (DX,AX)/ 源(字)的余数
(要是被除数只有16位,除数也是16位,必须把16位被除数放在AX中,并将DX清0,然后相除)
IDIV 整数除法指令
功能与DIV相同,但操作数都必须是带符号数,商和余数也都是带符号数,而且规定余数的符号和被除数的符号相同
CBW 把字节转换为字指令
将寄存器AL中字节的符号位扩充到AH的所有位
CWD 把字转换成双字指令
把AX中的字的符号位扩充到DX寄存器的所有位中去
AAD 除法的ASCII调整指令
NOT取反指令
将目的操作数求反
目的操作数可以是8位或16位寄存器或存储器,指令执行后,对标志位无影响
AND 逻辑与指令
对两个操作数进行按位逻辑与操作,结果返回目的操作数
OR 逻辑或指令
对两个操作数进行按位逻辑或操作,结果返回目的操作数
XOR 异或操作指令
对两个操作数进行按位逻辑异或运算,结果返回目的操作数
TEST 测试指令
对两个操作数进行按位逻辑与操作,并修改标志位,但不回送结果
SAL 算术左移指令
SHL 逻辑左移指令
上面两条指令的功能完全相同,均将寄存器或存储器中的目的操作数的各位左移,每移动一次,最低有效位LSB补0,最高有效位MSB进入标志位CF
SHR 逻辑右移指令
均将寄存器或存储器中的目的操作数的各位右移,每移动一次,最高位补0,最低位进入标志位CF
SAR 算数右移指令
目的操作数的各位右移,每移动一次,最低位进入标志位CF,但最高位(符号位)保持不变(即与之前最高位保持一致
ROL 循环左移指令
ROR 循环右移指令
RCL 通过进位位循环左移指令
RCR 通过进位位循环右移指令
目的操作数可以是8/16位的寄存器操作数或内存操作数,计数值含义同上,即1或由C指定。
ROL和ROR为小循环移位指令,没有把CF包含在循环中;RCL和RCR为大循环指令,把CF作为整个循环的一部分参加循环移位。
CF的值由最后一次被移出的值决定。OF的值只有在移动1次的指令中才有效,移位后符号位发生变换,则OF置1,否则OF置0
1 | 设 CF=1,AL=1011 0100B |
注意,在移位操作中,移位次数为多次时,必须将移位次数存放到CL寄存器中
MOVS 字符串传送指令
MOVS 目的串, 源串
把由SI作指针的源串中的一个字节或字,传送到由DI作指针的目的串中,且自动修改指针SI和DI
REP MOVSB 等价于
MOVS NEW_LOC, SRC_MESS
DEC CX
JNZ AGAIN
CMPS 字符串比较指令
SCAS 字符串扫描指令
LODS 数据串装入指令
STOS 数据串存储指令
将累加器AL或AX中的一个字节或字,传送到附加段中以DI为目标指针的目的串中,同时修改DI,以指向串中的下一个单元
JMP 无条件转移指令
使程序无条件的转移到指令中的目的地址去执行
过程调用和返回指令
CALL 过程名
RET
直接标志转移指令
| 指令助记符 | 测试条件 | 指令功能 |
|---|---|---|
| JC | CF=1 | 有进位 |
| JNC | CF=0 | 无进位 |
| JZ/JE | ZF=1 | 结果为零/相等 |
| JNZ/JNE | ZF=0 | 不为零/相等 |
| JS | SF=1 | 符号为负 |
| JNS | SF=0 | 符号为正 |
| JO | OF=1 | 溢出 |
| JNO | OF=0 | 无溢出 |
| JP/JPE | PF=1 | 奇偶位为1/为偶 |
| JNP/JPO | PF=0 | 奇偶位为0/为奇 |
间接标志条件转移指令
无符号数
JA/JNBE 高于/不低于等于
JAE/JNE 高于等于/不低于
JB/JNAE 低于/不高于等于
JBE/JNA 低于等于/不高于
带符号数
JG/JNLE 大于/不小于等于
JGE/JNL 大于等于/不小于
JL/JNGE 小于/不大于等于
JLE/JNG 小于等于/不大于
LOOP 循环指令
LOOPE/LOOPZ 相等或结果为0时循环
LOOPNE/LOOPNZ 相等或结果为不0时循环
INT n 软件中断指令
INTO 溢出中断指令
IRET 中断返回指令
1.处理器选择伪指令
2.段定义伪指令 ( SEGMENT ENDS为定界语句)
3.段约定伪指令
4.汇编结束伪指令
END 程序启动指令标号
汇编程序对END之后额语句将不再进行任何处理。DOS装载程序的可执行文件是,自动把标号所在段的段基址赋给CS,把标号所在单元的偏移地址赋给IP
5.DOS的返回
程序完成预定任务之后,必须返回DOS
返回DOS的3种方法:P27
第一种: MOV AH,4CH
INT 21H
第二种: INT 20H
第三种:MAIN PROC FAR
PUSH DS
SUB AX,AX
PUSH AX
…..
RET
MAIN ENDP
(1)exe文件
exe文件允许使用多个逻辑段,每个逻辑段不超过64KB,适合编写大型程序。
(2)com文件
com文件只允许使用一个逻辑段,即代码段。程序所使用的数据,可以集中设置在代码段的开始或末尾。需要使用ORG定位伪指令将程序的启动指令存放在代码段偏移地址为100H的单元。
ORG指令用于通知汇编程序,将下一条指令或数据存放在表达式给出的段内实际偏移地址。
DATA SEGMENT AT 0040H
ORG 0017H
KEYFLAG DB ?
DATA ENDS
定义了KEYFLAG变量,存放在段基址为40H,偏移地址为0017H的内存单元中。
1、调用模式:
MOV AH,功能号
如果有入口参数,设置入口参数
INT 21H
如果有出口参数,分析出口情况
2、功能号
01H号功能读字符,出口参数 AL=输入字符
02H号功能显示字符;入口参数 DL=显示字符的 ASCII 码
09H显示以 $ 结尾的字符串,入口参数 DS:DX=字符串首地址
0AH键盘输入字符串,从BUF+2单元开始存放,入口参数 DS:DX=字符串首地址
4CH功能返回DOS(返回DOS的操作系统),即程序终止
在循环程序中,常用计数器CX寄存器控制循环次数,每经过一次循环操作,计数器自动减1,减到0时,表示循环结束
LEA BX,DATA ;DATA偏移地址送BX
MOV CX,14 ;设循环次数
MOV AL,[BX] ;第一个带符号数送AL
CHECK: INC BX
CMP AL,[BX] ;两数比较
JNZ DONE ;如果AL中的数较小,则转DONE
MOV AL,[BX]
DONE: LOOP CHECK ;循环次数,CX=CX-1,当CX==0,结束循环,执行后续语句
MOV MIN,AL ;存放最小数
HLT
两个带符号数 1011 0100B 和 1100 0111B 相加,运算后各标志位的值等于多少?哪些标志位是有意 义的?如果把这两个数当成无符号数,相加后哪些标志位是有意义的?
答:
带符号数:
1 0111 1011
CF=1,有进位,对于带符号数,无意义
PF=1,结果有偶数个1
AF=0,无半进位,非BCD码运算,无意义
ZF=0,结果非0
SF=0,结果为正数
OF=1,溢出(两个负数相加,结果为正数)
无符号数:
1 0111 1011
CF=1,有进位
PF=1,结果有偶数个1
ZF=0,结果非0
AF、SF、OF无意义
如果从存储单元 2000H 开始存放的字节数据为:3AH,28H,56H,4FH,试画出示意图说明:从 2000H 到 2001H 单元开始取出一个字数据各要进行几次操作,取出的数据分别等于多少。
答:
(2000H)=3AH,(2001H)=28H,(2002H)=56H,(2003H)=4FH,从 2000H 取一个字要 1 次操作,数据为 283AH;从 2001H 取一个字要2次操作,数据为 5628H
分别说明下列指令的源操作数和目的操作数各采用什么寻址方式。
(1)MOV AX,2408H
(2)MOV CL,0FFH
(3)MOV BX,[SI]
(4)MOV 5[BX],BL
(5)MOV [BP+100H],AX
(6)MOV [BX+DI],’$’
(7)MOV DX,ES:[BX+SI]
(8)MOV VAL[BP+DI],DX
(9)IN AL,05H
(10)MOV DS,AX
答:
(1)立即数,寄存器
(2)立即数,寄存器
(3)寄存器间接,寄存器
(4)寄存器,寄存器相对
(5)寄存器,寄存器相对
(6)立即数,基址变址
(7)基址变址,寄存器
(8)寄存器,相对基址变址
(9)直接端口寻址,寄存器
(10)寄存器,寄存器
已知:DS=1000H,BX=0200H,SI=02H,内存10200H~10205H 单元的内容分别为10H, 2AH,3CH,46H,59H,6BH。下列每条指令执行完后AX 寄存器的内容各是什么?
(1)MOV AX,0200H
(2)MOV AX,[200H]
(3)MOV AX,BX
(4)MOV AX,3[BX]
(5)MOV AX,[BX+SI]
(6)MOV AX,2[BX+SI]
答:
(1)0200H
(2)2A10H
(3)0200H
(4)5946H
(5)46C3H
(6)6B59H
指出下列指令中哪些是错误的,错在什么地方。
(1)MOV DL,AX
(2)MOV 8650H,AX
(3)MOV DS,0200H
(4)MOV [BX],[1200H]
(5)MOV IP,0FFH
(6)MOV [BX+SI+3],IP
(7)MOV AX,[BX] [BP]
(8)MOV AL,ES:[BP]
(9)MOV DL,[SI] [DI]
(10)MOV AX,OFFSET 0A20H
(11)MOV AL,OFFSET TABLE
(12)XCHG AL,50H
(13)IN BL,05H
(14)OUT AL,0FFEH
答:
(1)长度不匹配
(2)立即数不能做目的操作数
(3)段寄存器不能用立即数赋值
(4)不能两个内存(目的数和源操作数不能同时为存储单元)
(5)IP 不能用指令直接修改
(6)指令中不能出现 IP
(7)BX/BP 应与 SI/DI 搭配
(8)对
(9)SI/DI 应与 BX/BP 搭配
(10)OFFSET 后应该跟内存
(11)应该用 AX
(12)不能立即数
(13)IN 必须用 AL/AX
(14)操作数反:地址应为8位
已知当前 SS=1050H,SP=0100H,AX=4860H, BX=1287H,试用示意图表示执行下列指 令过程中,堆栈中的内容和堆栈指针 SP 是怎样变化的
PUSH AX
PUSH BX
POP BX
POP AX

下列指令完成什么功能?
(1)ADD AL,DH
(2)ADC BX,CX
(3)SUB AX,2710H
(4)DEC BX
(5)NEG CX
(6)INC BL
(7)MUL BX
(8)DIV CL
答:
(1) AL+DH->AL
(2) BX+CX+CF->BX
(3) AX-2710H->AX
(4) BX-1->BX
(5) 0-CX->CX
(6) BL+1->BL
(7) AX*BX->DX
(8) AX/CL
寻址方式?
寄存器间接寻址、直接寻址、寄存器相对寻址、基址加变址寻址、基址加变址相对寻址。
数据操作数的种类?
立即数、寄存器数和内存单元数
段地址、偏移地址与物理地址之间的关系?有效地址EA又是指什么?
段地址左移四位加上偏移地址形成20位的物理地址。EA是指段内偏移地址,即表示段内某单元相对于段起始地址的空间位置。
能用于寄存器间接寻址及变址寻址的寄存器有哪些?它们通常与哪个段寄存器配合形成物理地址?
基址寄存器 BX 和 BP,变址寄存器 SI 和 DI
BX、SI、DI与DS配合形成物理地址,而BP与SS配合形成物理地址。
什么是堆栈操作?以下关于堆栈操作的指令执行后,SP的值变化是多少?
PUSH AX
PUSH CX
PUSH DX
POP AX
PUSH BX
POP CX
POP DX
堆栈被定义为一种先进后出的数据结构,即最后进栈的元素将被最先弹出来。堆栈从一个称为栈底的位置开始,数据进入堆栈的操作称为压入(或压栈),数据退出堆栈的操作称为弹出,每进行一次弹出操作,堆栈就减少一个元素,最后一次压入的元素,称为栈顶元素,压入弹出操作都是对栈顶元素进行的堆栈的两种基本的操作。
在进行以上一系列堆栈操作后,SP指针的值是原 SP-2。
用汇编语言指令实现以下操作
(1)将寄存器AX、BX和DX的内容相加,和放在寄存器DX中。
ADD AX,BX
ADD DX,AX
(2)用基址变址寻址方式(BX和SI)实现AL寄存器的内容和存储器单元BUF中的一个字节相加的操作,和放到AL中。
ADD AL,BYTE PTR [BX] [SI]
BYTE PTR[DI] 表示指向的值是个BYTE (一字节)
(3)用寄存器BX实现寄存器相对寻址方式(位移量为100H),将DX的内容和存储单元中的一个字相加,和放到存储单元中。
ADD 100H[BX],DX
(4)用直接寻址方式(地址为0500H)实现将存储器中的一个字与立即数3ABCH相加,和放回该存储单元中。
ADD [0500H],3ABCH
(5)用串操作指令实现将内存定义好的两个字节串BUF1和BUF2相加后的和,存放到另一个串BUF3中的功能。
1 | …… |
指出下列指令中,源操作数及目的操作数的寻址方式。
SUB BX,[BP+35] ;寄存器寻址、寄存器相对寻址
MOV AX,2030H ;寄存器寻址、立即寻址
SCASB ;隐含操作数为寄存器寻址和寄存器间接寻址
IN AL,40H ;寄存器寻址、立即寻址
MOV [DI+BX],AX ;基址加变址寻址、寄存器寻址
ADD AX,50H[DI] ;寄存器寻址、寄存器相对寻址
MOV AL,[1300H] ;寄存器寻址、直接寻址
MUL BL ;寄存器寻址、目的操作数为隐含寄存器寻址
已知(DS)= 1000H,(SI)= 0200H,(BX)= 0100H,(10100H)= 11H,(10101H)= 22H,(10600H)= 33H,(10601H)= 44H,(10300H)= 55H,(10301H)= 66H,(10302H)= 77H,(10303H)= 88H,试分析下列各条指令执行完后AX寄存器的内容。
1 | MOV AX,2500H (AX)=2500H |
判断下列指令是否有错,如果有错,说明理由。
| SUB BL,BX | 两个操作数的宽度不一样 |
|---|---|
| MOV [DI],[SI] | 两个操作数不能同时为内存数 |
| MOV AX,BYTE PTR[SI] | 源操作数限定为字节,与目的操作数宽度不一致 |
| MOV 125,CL | 立即数不能做目的操作数 |
| MOV CS,BX | 不能对CS实现传送操作 |
| SHR AX,4 | 只有当移位位数为1时,才能用立即数表达 |
| MOV AH,[SI] [DI] | 不能用两个变址寄存器来实现寻址操作 |
| SHL AX,CH | 移位指令的移位位数用CL给出,不能用CH。 |
| MOV BYTE PTR[BX],3456H | 将16位的立即数传送到一个字节的内存单元 |
设(DS)= 1000H,(ES)= 2000H,(SS)= 3000H,(SI)= 0080H,(BX)= 02D0H,(BP)= 0060H,试指出下列指令的源操作数字段是什么寻址方式?它的物理地址是多少?
1 | MOV AX,0CBH 立即寻址 |
分别说明下列每组指令中的两条指令的区别.
(1) AND CL,0FH 按位相“与”,高4位为“0000”,低4位保留原值;
OR CL,0FH 按位相“或”,高4位为原值,低4位为“1111”。
(2) MOV AX,BX 将BX寄存器的内容传送到AX寄存器中;
MOV AX,[BX] 将BX寄存器所指的内存单元的内容送AX寄存器中。
(3) SUB BX,CX BX寄存器内容减去CX寄存器的内容,结果送回到BX;
CMP BX,CX BX内容减去CX内容,结果只影响标志位。
(4) AND AL,01H AL内容与01H相“与”,结果为“0000000x”送回AL寄存器;
TEST AL,01H AL内容与01H相“与”,结果只影响标志位(ZF)。
(5) JMP NEAR PTR NEXT NEXT所指指令在当前指令的同段内;
JMP SHORT NEXT NEXT所指指令在当前指令的8位地址范围内。
(6) ROL AX,CL 循环左移,进位标志位不参与循环;
RCL AX,CL 循环左移,进位标志位参与循环。
(7) PUSH AX 将AX内容存入栈顶指针处,即进栈操作;
POP AX 将栈顶内容弹出装入AX寄存器中,即出栈操作。
试分析以下程序段执行完后BX的内容为何?
MOV BX,1030H
MOV CL,3
SHL BX,CL 逻辑左移,BX= 1000 0001 1000 0000 = 8180H
DEC BX 减一
程序执行完后,BX=817FH
编写能实现以下功能的程序段。
根据CL中的内容决定程序的走向,设所有的转移都是短程转移。若D0位等于1,其他位为0,转向LAB1;若D1位等于1,其他位为0,转向LAB2;若D2位等于1,其他位为0,转向LAB3;若D0、D1、D2位都是1,则顺序执行。
1 | …… |
写出下列指令序列中每条指令的执行结果,并在DEBUG环境下验证,注意各标志位的变化情况。
MOV BX,126BH (BX=126BH)
ADD BL,02AH (BX=1295H)
MOV AX,2EA5H (AX=2EA5H)
ADD BH,AL (BX=B795H)
SBB BX,AX (BX=88F0H)
ADC AX,26H (AX=2ECBH)
SUB BH,-8 (BX=90F0H)
程序段1:
MOV AX,4455H
MOV BX,7722H
PUSH AX
POP CX
XCHG BX, CX
程序执行后 AX = 4455H, BX = 4455H, CX = 7722H.
程序段2:
MOV AX, 8765H
MOV DX,4321H
MOV CL,04
SHL DX,CL (DX=3210H)
MOV BL,AH (BL=87H)
SHL AX,CL (AX=0111 0110 0101 0000=7650H)
SHR BL,CL (BL=08H)
OR DL,BL (DL=18H)
程序执行后 AX= 7650H, DX= 3218H
程序段3:
TABLE DW 11H,2233H,4455H,6677H,88H
…
MOV BX, OFFSET TABLE
MOV AX, [BX]
MOV DX, [BX+3]
程序执行后,AX = 0011H, DX= 5522H
1 | 0000:11 BX |
设BX=0123H,DI=1000H,DS=3200H,试指出下列各条指令中源操作数的寻址方式,对于是存储器操作数的,还需写出其操作数的有效地址和物理地址。
(1)MOV AX,[2A38H]
(2)MOV AX,[BX]
(3)MOV AX,[BX+38H]
(4)MOV AX,[BX+DI]
(5)MOV AX,[BX+DI+38H]
(6)MOV AX,2A38H
(7)MOV AX,BX
参考答案:
(1)直接寻址 有效地址=2A38H,物理地址=32000H+2A38H=34A38H
(2)寄存器间接寻址 有效地址=0123H,物理地址=32000H+0123H=32123H
(3)寄存器相对寻址 有效地址=0123H+38H=015BH,物理地址=32000H+015B=3215BH
(4)基址变址寻址 有效地址=0123H+1000H=1123H,物理地址=32000H+1123H=33123H
(5)相对基址变址寻址 有效地址=0123H+1000H+38H=115BH,物理地址=32000H+115BH=3315BH
(6)立即寻址
(7)寄存器寻址
设AX=96BCH,BX=AC4DH,CF=0。求分别执行指令ADD AX,BX和SUB AX,BX后,AX与BX的值各为多少?并指出标志位SF、ZF、OF、CF、PF、AF的状态。
参考答案:
执行ADD AX,BX后,AX=4309H,BX= AC4DH ,SF=0 ZF=0 OF=1 CF=1 PF=1 AF=1
执行SUB AX,BX后,AX=EA6FH,BX= AC4DH ,SF=1 ZF=0 OF=0 CF=1 PF=1 AF=1
采用三种不同的方法实现AX与DX的内容交换
参考答案:
第一种:XCHG AX,DX (XCHG 把源操作数和目的操作数相交换)
第二种:PUSH AX
PUSH DX
POP AX
POP DX
第三种:MOV BX,AX
MOV AX,DX
MOV DX,BX
编写程序段实现:当DL中存放的数据是奇数时使AL=1,否则使AL=-1
参考答案:
1 | TEST DL,01H (逻辑与操作,但不回送结果,检查DL的最低位是否为1) |
用尽可能少的指令实现使DL中的高4位内容与低4位内容互换
参考答案:
MOV CL,4
ROL DL,CL 或 ROR DL,CL
编写程序段,判断AL中的带符号数是不是负数。若是负数,则将-1送给AH;否则,将1送给AH
参考答案:
1 | SUB AL,0 |
假设DX=87B5H,CL=4,CF=0,确定下列各条指令单独执行后DX中的值
(1)SHL DL,1
(2)SHR DX,CL
(3)SAR DX, CL
(4)ROL DX,CL
(5)ROR DX,CL
(6)RCL DX,CL
(7)RCR DX,1
参考答案:
(1)DX=876AH
(2)DX=087BH
(3)DX=F87BH
(4)DX=7B58H
(5)DX=587BH
(6)DX=7B54H
(7)DX=43DAH
按下列要求编写指令序列。
(1)将AX中的低4位置1,高4位取反,其它位清0。
(2)检查DX中的第1、6、11位是否同时为1。
(3)清除AH中最低3位而不改变其它位,将结果存入BH中。
参考答案:
(1)XOR AX,F000H //异或取反
AND AX,F00FH //其他位清零
OR AX,000FH //低四位置1
(2)MOV AX,DX
AND DX,0842H //(0000 0100 0010 0010 最右端那一位为b0,最高位是b15,第1、6、11位为b1,b6,b11)
XOR DX,0842H
JZ ZERO
…
ZERO: … DX中的第1、6、11位同时为1的情况
…
(3)AND DH,0F80H
MOV BH,DH
分析下面的程序段完成什么功能?(提示:请将DX与AX中的内容作为一个整体来考虑)
MOV CL, 04 (将4存入CL中)
SHL DX, CL (DX逻辑左移4位,DX最低4位为0)
MOV BL, AH (将AH中内容存入BL,以免AX左移4位时高4位丢失)
SHL AX, CL (AX逻辑左移4位)
SHR BL, CL (BL逻辑右移4位,这样AX原来的最高4位就放到BL的低4位了)
OR DL, BL (DL与BL按位逻辑或操作,结果返回DL,也就是把AX原来的最高四位写入到DX的最低四位)
参考答案:DX和AX中联合存放一个32位的二进制数(DX存放高16位),这个程序段把它逻辑左移4位。
设SS=1000H,SP=2000H,AX=345AH,BX=F971H,Flags=4509H,试分析执行以下指令
PUSH BX
PUSH AX
PUSHF (将标志寄存器Flags的值压入堆栈顶部, 同时栈指针SP值减2)
POP CX
之后,SP、SS、CX的值各为多少?
参考答案:SP=1FFCH SS=1000H CX=4509H
指出下列指令中哪些是错误的,并说明错误原因
1 | (1)MOV DL,CX (2)MOV DS,1000H |
参考答案:
(1)数据类型不匹配 (2)立即数不能送段寄存器
(3)两个存储器操作数之间不能直接传送数据
(4)源操作数寻址不能为基址加基址
(5)正确 (6)PUSH指令的操作数不能为立即数
(7)存储器操作数类型不明确 (8)CS不能作为目的操作数使用
(9)目的操作数类型需明确 (10)两个操作数数据类型不匹配
已知各寄存器和存储单元的状态如图3.19所示,请阅读下列程序段,并将中间结果填入相应指令右边的空格
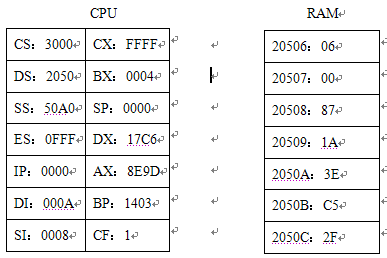
1 | MOV DX,[BX+4] ; DX=( 1A87H ) |
假设以1000H为起始偏移地址的内存单元内容显示如图3.20所示,请指出在DEBUG下如下每条指令的寻址方式及执行后的结果
MOV AX,1000
MOV BX,AX
MOV AX,[BX]
MOV AX,10[BX]
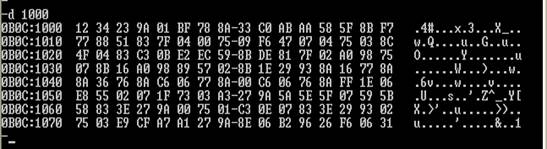
参考答案:
MOV AX,1000 ;立即寻址,AX=1000H
MOV BX,AX ;寄存器寻址,BX=1000H
MOV AX,[BX] ;寄存器间接寻址,AX=3412H
MOV AX,10[BX] ;寄存器相对寻址,AX=8877H
设AL=86H,BL=21H,在分别执行MUL和IMUL指令后,各自的结果是多少?OF=?,CF=?
参考答案:
执行MUL BL后,结果AX=1146H;OF=1,CF=1
执行IMUL BL后,结果AX=F046H;OF=1,CF=1
开发汇编语言源程序的主要步骤有哪些?
(1)问题定义
(2)建立数学模型
(3)确立算法和处理方案
(4)画流程图
(5)编制程序
(6)上机调试
(7)试运行和分析结果
(8)整理资料,投入运行
简述衡量一个程序质量的标准
程序的正确性和完整性。
程序的易读性。
程序的执行时间和效率。
程序所占内存的大小。
循环程序由几部分组成?各部分的功能是什么?
循环初始化部分。这是循环准备工作阶段,如建立地址指针、设置循环次数、必要的数据保护以及为循环体正常工作而建立的初始状态等。这一部分本身只执行一次。
循环体。即循环程序要完成的具体操作,是需要重复执行的程序段。它是循环的核心部分,没有循环体就不能构成循环。
循环控制部分。循环控制部分主要用来结束整个循环过程,根据循环所给定的条件,判别循环是否结束,完成对循环的控制。
循环控制修改部分。这一部分是为保证每一次循环时,参加执行的信息能发生有规律的变化而建立的程序段。循环控制主要是一些运算控制单元(变量、寄存器)的修改间距、修改操作数地址、修改循环计数器、改变变量的值等。
常用循环程序的控制方法由哪几种?阐述每种的特点
控制循环次数较常用的方法是用计数器控制循环、按问题的条件控制循环和用逻辑变量控制循环。
计数器控制循环就是利用循环次数作为控制条件,它是最简单的和典型的循环控制方法。对于循环次数已知的程序,或者在进入循环前可由某个变量确定循环次数的程序,通常用计数器来控制循环。这种情况适于采用循环指令LOOP来实现循环功能。
有些循环程序的循环次数事先无法确定,但它与问题的某些条件有关。这些条件可以通过指令来测试。若测试比较的结果满足循环条件,则继续循环,否则结束循环。这就是所谓的按问题的条件控制循环。事实上,利用条件转移指令支持的转移条件作为循环控制条件,可以更方便地构造复杂的循环程序结构。
在有些情况下,可能在一个循环中有两个循环支路,在第一个支路循环了若干次以后,转至另一个循环支路循环。这就可以设置一个逻辑变量,用以控制转入不同的循环支路。具体实现方法是:把逻辑变量送入寄存器中,以逻辑变量各位的状态作为执行某段程序的标志。逻辑变量可由一到多个字节组成。
在内存BUFFER单元中定义有10个16位数,试寻找其中的最大值及最小值,并放至指定的存储单元MAX和MIN中。画出程序流程图。
1 | DATA |
统计字型变量DATBUF中的值有多少位为0,多少位为1,并分别记入COUNT0及COUNT1单元中
编程思路:
在内存单元定义一个变量DATBUF,将其取到寄存器中,采用移位的方式识别每一位为0还是为1,设置两个计数器分别统计。统计好后,分别存入内存单元。
1 | DATA |
设在变量单元A1、A2、A3、A4中存放有4个数,试编程实现将最大数保留,其余三个数清零的功能。
编程思路:
依次比较各个数,每次比较将较小的数清零,较大数及较大数的地址保留,再继续与下一个数比较,直至四个数处理完。
1 | DATA |
在BUFF开始的存储区中存放30个带符号数,试统计其正数、负数和零的个数。并将个数分别放至A1、A2及A3单元
编程思路:
将30个符号数依次取到寄存器中,判断每个数的符号位,依此可识别出负数和非负数,再判断是否为0,可识别出是零还是正数。设置3个计数器分别统计正数、负数和零的个数,统计完后存入内存单元。
若在内存缓冲区中存在一个无序列,列的长度放在缓冲区的第一个字节,试将内存某单元中的一个数加入到此数列中(若此数列中有此数,则不加;若此数列中无此数,则加在数列尾)
编程思路:
将内存定义好的数串元素依次取到寄存器中,与要加入的数据比较;
如非此数,取下一个数继续比较;
如是此数,则停止比较,结束
如比较结束也无此数,则将该数加到数尾,并且列的长度加1;结束
1 | DATA |
在内存已定义好一个容量为20字节的数组,请将数组中为0的项找出,统计0的个数,并删除数组中所有为零的项,将后续项向前移动,进行压缩处理
编程思路:
将数组依次取到寄存器中,每个数与零比较;
统计0的个数;
每次发现为0的项,统计后将其删掉,后续项向前移。
1 | DATA |
将内存字单元BUF1中的内容拆为四个16进制数,并分别转换为相应的ASCII码存于BUF2及其后续的单元中
1 | STACK STACK |
在数据段的BUFFER到BUFFER+24单元中存放着一个字符串,请判断该字符串中是否存在数字,如有则把X单元置1,如无数字则将X单元置0
编程思路:
(1)将字符串依次取到寄存器中;
(2)将字符的ASCII码与30H~39H比较,在此范围则为数字;
(3)发现数字,则置X单元为1,并结束搜索。
1 | DATA |
从键盘上输入两个字符存于A,B单元中,比较它们的大小,并在屏幕上显示两个数的大小关系
1 | STACK STACK |
内存BUF开始的单元中存放6个无序数,请用冒泡法将它们按递增顺序排序
1 | STACK STACK |
编写程序,求1~150之间的能同时被2和3整除的整数之和
编程思路:
从1开始判断每个数是否能被2整除,不能被2整除则更新为下一个数;
能被2整除则再判断是否能被3整除,如能整除则累加该数;
当该数更新为150时,则停止
阅读下列程序,写出程序执行后,数据段BUF中十个内存单元中的内容
1 | DATA |
分析以下程序段的功能,并指出程序执行后BUF单元存储的是什么信息?
1 | DATA |
程序执行后,BUF中存放STRN的实际长度(即字符个数)。包括“$”吗?
BUF中存放字符串中第一个‘$’的位置
子程序是如何定义和调用的?
子程序的定义是由过程定义伪指令来实现的,一个过程是一段程序,以PROC伪指令语句开始,以ENDP伪指令语句结束。格式如下:
过程名 PROC [NEAR或FAR]
…
过程名 ENDP
子程序(过程)调用指令CALL的格式为:
CALL OPRD
什么是子程序的嵌套和递归?
一个子程序可以作为调用程序去调用另一个子程序,这种情况就称为子程序的嵌套。嵌套的层次不限,其层数称为嵌套深度。嵌套子程序的设计并没有什么特殊要求,除子程序的调用和返回应正确使用CALL和RET指令外,要注意寄存器的保存和恢复,以避免各层子程序之间发生因使用寄存器冲突而出错的情况。
在子程序嵌套的情况下,如果一个子程序调用的子程序就是它自身,这就称为递归调用。这样的子程序称为递归子程序。在子程序递归调用时,也不可避免地要用到堆栈,所以递归调用的嵌套层数往往会受堆栈容量的限制。
主程序和子程序之间的参数传递主要有几种方式?每种方式的特点是什么?
(1)利用寄存器传递参数
这是最常用的一种方法,但受到寄存器个数的限制,一般用于参数较少的情况。在主程序中将要传递的参数放入到指定的寄存器中,然后在子程序中再从相应的寄存器获取参数。
(2)利用内存缓冲区传递参数
用存储器传递参数的最简单方法是定义位置、格式确定的缓冲存储区,凡是需要过程处理的参数,无论原来存在什么地方,必须按格式要求先传入缓冲区。过程从缓冲区取得数据进行规定的处理,产生的结果按格式要求存入这个或另外的缓冲存储区,调用程序(主程序)再从缓冲区取走结果。
(3)利用堆栈区传递参数
将子程序(过程)要用的参数放在堆栈区中,设置好指针(BP),子程序(过程)执行时从堆栈区取出参数,完成相应的功能。
试编写能实现如下功能的过程
(1)十进制数转换为ASCII码
1 | SUB1 PROC FAR |
(2)十六进制数转换为ASCII码
1 | SUB1 PROC FAR |
(3)数字的ASCII码转换为十六进制数
1 | SUB1 PROC FAR |
(4)f(x) = 2x^2 +3x–4
1 | SUB1 PROC FAR |
(5)非压缩BCD码转换为压缩BCD码
1 | BCDTR1 PROC NEAR |
(6)压缩BCD码转换为非压缩BCD码
1 | BCDTR2 PROC NEAR |
下面的子程序有错吗?如果存在错误,将其改正。
1 | ABC PROC |
说明:调用此子程序前,在调用程序中需要对BX(累加数据区的首地址)和CX(累加的字个数)进行初始化;并且在调用程序前AX和DX没有被使用;子程序执行后的返回值(数据区的字累加和)在AX和DX中。(子程序利用寄存器传递地址参数,但真正的数据是在存储区中)
子程序的功能是什么?
分析下面程序段,程序运行后,AL和BL寄存器中的内容是什么?
| … | |||
|---|---|---|---|
| XOR AL,AL | AL =0 | ||
| CALL SUBROUT | |||
| MOV BL,AL | BL = AL=11111111 | ||
| CALL SUBROUT | |||
| RCR AL,1 | AL =1000 0000 | ||
| HLT | |||
| SUBROUT PROC NEAR | |||
| NOT AL | AL=11111111 | AL=00000000 | |
| JS NEXT | SF=1 | ||
| STC | CF=1 | ||
| NEXT: RET | |||
| SUBROUT ENDP | |||
| … |
1 | ... |
程序运行后,AL的内容为10000000B;BL的内容为11111111B;(利用寄存器传递参数)
分析下列程序,指出程序完成什么功能?
1 | MAIN PROC FAR |
MAIN中初始化源串和目的串,并调用子程序REMOV;子程序REMOV实现字节型数据串的传送。(利用堆栈传递参数)
MAIN中初始化源串和目的串,并调用子程序REMOV;子程序REMOV实现字节型数据串的传送。(利用堆栈传递参数)
1 | STACK STACK |
设计一个子程序,它能完成在屏幕上输出空行的功能,空行的行数在CX寄存器中。试将此功能用于你的程序中。
1 | DISP PROC NEAR |
编程(包含子程序)实现对两个数组求和的功能,设两个数组的类型相同,数组元素个数也相同。
编程思路:
依次取出两个数组的元素,按序相加,结果存放在和数组中;设置一个计数值,控制加法的次数。
什么叫DOS系统功能调用?什么叫BIOS系统功能调用?
在多用户和多任务的环境下,与硬件有关的ROMBIOS资源只允许操作系统这个特殊用户使用,用户只可以使用INT 21H功能调用,包括字符输入、字符输出、磁盘控制、文件管理、记录操作、目录操作、动态存储分配等功能。
IBMDOS.COM包括一个文件管理程序和一些处理程序,在DOS下运行的程序可以调用这些处理程序。IBMDOS.COM是通过把信息传送给IBMBIO.COM,形成一个或多个BIOS调用,来完成DOS功能调用的。
BIOS存放在内存的最高端,是由功能模块组成的,可以通过软中断指令调用这些功能模块,故又称为BIOS中断调用。ROM BIOS使用了中断向量码00H~1FH。
例如:键盘I/O中断调用INT 16H
该中断调用16H有三个功能,功能号0~2。
(AH)= 0为从键盘读字符到AL寄存器中。
入口参数:无。
出口参数:AL中为键入字符的ASCII码,AH为键入字符的扫描码。
调用方法为:
MOV AH,0
INT 16H
举例说明实现DOS系统功能调用的一般步骤。
中断类型21H是DOS功能调用的主体,它提供了众多的非常强大的功能供用户调用,功能号由寄存器AH提供。在发INT 21H软中断之前,应该先准备好入口参数(也称调用参数),并将功能号送入AH寄存器中。
例如:由键盘输入单个字符
MOV AH,1 ;系统调用功能号送AH
INT 21H
输入字符的ASCII码在AL寄存器中,同时字符显示在屏幕上。
用系统功能调用实现:把键盘输入的十进制数转换为二进制数,并将结果存放到内存单元。
编程思路:
定义键盘输入功能;
将带符号的十进制数转换为二进制数,此功能可以定义子程序实现;
将转换后的结果存放到内存单元。
分别用字符显示功能和字符串显示功能来完成在屏幕上显示一个字符串“STUDENT”的功能
1 | STACK STACK |
从键盘上输入一行字符,如果这行字符的长度是10,则保存该行字符。然后继续输入下一行字符。按下‘$’输入结束,最后将所有保存的字符串都显示在屏幕上。
编程思路:
在内存设置缓冲区;
通过键盘输入字符,边输入边统计,并存入内存单元;
到10个字符,则回车换行;
再继续输入;
判断输入字符是否为‘$’,以此决定是否结束,若结束,将内存缓冲区的字符显示在屏幕上。
1 | DATAS |
利用DOS系统功能调用,实现键盘屏幕方式的人机对话。
对话内容如下:
Please input a key (0-9).
The key is 8(输入的数字显示在此)
编程思路:
利用字符串显示方式在屏幕当前光标位置显示如下信息:
Please input a key (0-9).
The key is
启动键盘输入字符,判断是否数字,若数字,则保留;
将输入的数字显示在当前光标位置
简述汇编程序的执行过程
编辑程序->*.ASM文件->汇编程序MASM->*.OBJ文件->连接程序LINK->*.EXE文件
汇编程序有哪些功能?
检查出源程序中的语法错误,并给出出错信息提示。
生成源程序的目标代码程序,也可给出列表文件。
汇编时遇到宏指令即展开
简述典型微机操作系统的特点
Windows是微软公司最初在1985年底推出的专用于微型机的操作系统,第一个版本称为Windows 1.0,后来不断更新。随着版本的不断提高,功能不断加强,速度也不断提高。Windows的操作简单,体现在用户界面的高度图形化和选择性上。Windows完全不需要用户自己输入计算机命令,而是像“点菜”一样从给出的命令选单中作出选择,就能得心应手地操纵计算机的运行。Windows的操作简单,也体现在添加新的硬件设备时所提供的即插即用功能。从Windows 95版本开始,微软公司就在Windows设计中容纳了网络驱动程序,并考虑了对网络协议的接纳。由于Windows有良好的兼容性,所以,在系统中既可以运行16位的程序,也可以运行32位的程序。而且,Windows对硬件也实现了良好的兼容,允许在计算机系统中接入当今市场上能与微型机相连的各种外设。
自己搜集的题目
8086CPU 是一个 16位的微处理器,具有 16 位数据总线,20 位地址总线,可寻址空间为 1M 字节
在 PC 机中,只能用 10 根地址线对 I/O 端口寻址,可寻址的端口有 B 个
A.256 B.1K C.64K D.1M
数制转换
[124.719]10 = [1111100.10111000]2 = [7C.B8]16 = [235.5014]7 = [00100100100.011100011001]BCD
代码转换
[-104]10=[11101000]原=[10010111]反=[10011000]补
16 位二进制补码所能表示的最大数是 A
A.32767 B.32768 C.65535 D.65536
下面指令序列测试 AL 中的数是否偶数,若为偶数则转移至 NEXT 处,横线处的指令为 B
TEST AL,01H
__ NEXT
A.JNZ B.JE C.JS D.JC
用来存放下一条要取指令的偏移地址的寄存器是 A
A.IP B.FLAGS C.BP D.SP
下面指令中会影响状态标志的是 D 指令
A.MOV B.LEA C.PUSH D.CMP
寄存器间接寻址时,不可以提供偏移地址的寄存器是 A
A.DX B.BP C.DI D.BX
8086 系统中,一个堆栈段中最多可以存放 C 个字型的数据
A.1M B.64K C.32K D.1K
8086/8088 微机系统内存单元的物理地址是 D 位的
A.16 B.8 C.32 D.20
8086 CPU 执行一次 PUSH 指令,堆栈指针 SP 的值 D
A.加1 B.加2 C.减1 D.减2
如果AL的内容为50H,执行TEST AL,01H 指令后,AL的内容为 C
A.49H B.4FH C.50H D.01H
8086/8088 CPU分成 C 两个部分,它们是并行工作的
A.ALU和Cache B.ALU和BLU C.EU和BIU D.EU和Cache
电子计算机的发展历程是( )、晶体管时代、( )、( )
系统总线分为数据总线、( )总线和 ( )总线三种
8086/8088 系统中,存储器的逻辑地址包括( )地址和( )地址
8086/8088 系统中,存储器是分段组织的,每段最大长度是( )字节
指令一般包括 ( )、( )两部分
在8086/8088的通用寄存器AX、BC、CX、DX中,用作存储器间址的寄存器为?用作循环控制指令(LOOP)的寄存器为?
8086/8088的四个寄存器?用来存放数据段首地址的寄存器?用来存放代码段首地址的段寄存器?用来存放堆栈段首地址的段寄存器?
程序设计的基本结构有顺序结构、()、()
打印机是( )设备、扫描仪是( )设备
已知数据段有 100 个字节,DS=1200H,分别计算数据段段首、末单元的物理地址
12000H、12063H
判断下列指令的正误,如果有错则简单说明错误原因
SUB DATA1,[SI] 错,同为存储器操作数
MUL 50H 错,不能是立即数
MOV AX,[BX+1] 正确
XOR AX,[DX] 错,不能用 DX 间接寻址
分别写出完成下面各任务的指令
将AL寄存器的高四位置1,低四位保持不变 OR AL 0F0H
将BX寄存器中的带符号数除以8 MOV CL,3 SAR BX,CL
将DL寄存器中的小写字母的ASCII码转换为相应的大写字母 AND DL,0DFH
下面程序段实现的完整功能是:
1 | SHL BX,1 |
答:在显示器上显示BX的最高位,0或1
打印所有ASCII字符(1-FFH)
1 | //直接输出 |
输出“Hello World”
1 | DATAS |
DATA 开始的单元存放 15 个 8 位无符号数,要将其中的最小数找出来并存放在MIN单元。写出完成此功能的汇编语言程序片段
1 | LEA BX,DATA ;DATA偏移地址送BX |
选择题(~16%
填空题(~25%
简答题(~20%
程序阅读与理解(~25%
设计(程序)(~14%
绪论
计算机中数的表示方法
进制、码制
计算机的基本结构
冯诺依曼结构
微型计算机结构和系统
三大总线、存储器
微型计算机的发展概况
8086微处理器
8086 CPU的内部结构
基本功能模块、寄存器
8086/8088 CPU的引脚功能
8086的存储器组织
段地址和偏移地址、存储器的分体结构
寻址方式和指令系统
8086的寻址方式
操作数种类、寻址方式
指令的机器码表示方法(了解)
8086的指令系统
数据传送指令
算术运算指令
逻辑运算和移位指令
字符串处理指令
控制转移指令
汇编语言程序设计
终结符和非终结符
终结符可以简单地理解为「推导到这里就终结了」,也就是说不能再继续通过生成式向下推倒的元素就是终结符。
比如 T->abc。T 推导为串 abc 后已经得到了实质上的字符,不用在向下推导了,那么 T 为非终结符,abc 无法继续推导,则为终结符。(在一系列生成式中,式子左边的一定是非终结符,从未出现在式子左边的一定是终结符)
句子与句型
如果符号串x是由起始符号推导出的,则称x是文法G[S]的句型。
如果x中只包含终结符,则称x是文法G[S]的句子。
文法描述的语言是该文法一切句子的集合。
四种文法
0型文法:α→β,其中α至少包含一个非终结符。
1型文法(上下文有关文法):α→β,其中|β|≥|α|,S→ε除外。
2型文法(上下文无关文法):a→β,其中a是一个非终结符。
3型文法(规范文法):A→a或A→aB.
4种文法是逐渐增加限制的,所以规范文法一定是0型文法、1型文法、2型文法,上下文无关文法也一定是0型文法、1型文法…
上下文有关文法与上下文无关文法
在应用一个产生式进行推导时,前后已经推导出的部分结果就是上下文。上下文无关指,只要文法的定义里有某个产生式,不管一个非终结符前后的串是什么,就可以应用相应的产生式进行推导。
上下文无关文法例子:
1 | Code |
这个文法可以生成如下句子(共 16 种组合):
{人吃饭,天下雨,人吃肉,天下雪,人下雪,天下饭,天吃肉,……}
可以看到,其中有一些搭配在语义上是不恰当的,例如”天吃肉“。其(最左)推导过程为:
Sent -> SVO -> 天VO -> 天吃O -> 天吃肉
而上下文有关文法例子如下:
1 | Code |
可以看到,这里对 V 的推导过程施加了约束:虽然 V 还是能推出”吃“和”下“两个词,但是仅仅当 V 左边是”人“时,才允许它推导出”吃“;而当 V 左边是”天“时,允许它推导出”下“。这样通过上下文的约束,就保证了主谓搭配的一致性。类似地,包含 O 的产生式也约束了动宾搭配的一致性。(就是语法的强约束条件,导致上下文有关了)
这样一来,这个语言包含的句子就只有{人吃饭,天下雨,人吃肉,天下雪}这四条,都是语义上合理的。
以”人吃饭“为例,推导过程为:
Sent -> SVO -> 人VO -> 人吃O -> 人吃饭
(这与语法的歧义性还是不同的,要有所区分)
1型文法比2型文法识别的语言集合更大?
上例看到,感觉上下文有关文法所解释的句子集合更少。
这里的“1型文法比2型文法识别的语言集合更大” 这里的集合不是产生的结果集(字符串集合),而是语言规则集。 2型文法规则一定是1型文法规则,而有些语言能用1型文法规则描述,但用2型文法规则描述不出来。
例如 E+E (i+i):
最左推导是指:任何一步α=> β都是对α中的最左非终结符进行替换。
同样,可定义最右推导(又称规范推导):任何一步α=>β都是对α中的最右非终结符进行替换。
由规范推导所得到的句型称为规范句型。
(要证明某句型为左(右)句型,即最左(最右)推导能推导出该句型)
一个文法的某个句子对应两棵不同的语法树,则这个文法是二义的。
或一个文法的某个句子有两个不同的最左(右)推导,则这个文法是二义的。
人们已证明,二义性问题是不可判定的,即不存在一个算法,它能在有限步骤内,确切地判断一个文法是否是二义的。(做题时就画两颗不同的语法树来证明其二义性)
基本思想:从文法的开始符号出发,反复使用各种产生式,寻找“匹配”输入符号串的推导。即对任何输入符号串,从文法的开始符号(根结)出发,自上而下地为输入串建立一棵语法树,直到语法树结果正好是输入的符号串为止。
基本思想:从输入串开始,逐步进行“归约”,直至归约到文法的开始符号。即从语法树的末端开始,步步向上“归约”,直到根结。
短语
令文法G,开始符号为S,αβδ是G的句型(即S=>αβδ),如果S=>αAδ且A=>β,则称β是句型αβδ相对于非终结符A的短语。
(非终结符不断推导,只剩不能推导的符号)
直接短语
如短语中有A=>β,则称β是句型相对于规则A→β的直接短语。
(非终结符一次推导,只剩不能推导的符号,才能称为直接短语)
句柄
一个句型的最左直接短语称为该句型的句柄。
⒈ 先证明前提
⒉ 给出语法树(注意文法是否是二义性的)
如题文法G[E]: E→ E+E|E*E|(E) | i
证明i+i*i是G的一个句型,并指出这个句型的所有短语、直接短语、句柄。
⒊ 根据每棵语法树得出短语、直接短语、句柄
(注意编号)
(1)ε_closure(I) ——状态集合I的ε闭包(等价状态集)
设I是状态集的一个子集,ε_closure(I)定义为:
a.若S∈I,则S∈ε_closure(I);
b. 若S∈I,那么从S出发经过任意ε弧而能到达的任意状态S’都属于ε_closure(I);
(2)Move(I, a)——状态集合I的a弧转换
假定I是状态集的一个子集,a是Σ中的一个字符,定义
Ia = ε_closure(J)
其中J是所有那些可从I中的某一状态出发经过一条a弧而到达的状态结的全体。
(3)Ia= ε_closure(Move(I, a))
为了方便起见,令Σ中只有a,b两个字母,即Σ={a, b}
(1)构造一张表,此表的每一行有三列,第一列为I,第二列为Ia,第二列为Ib。即
| I | Ia | Ib |
|---|---|---|
| ε_closure(K0) |
首先置该表的第一列为ε_closure(K0)
(2)一般而言,若某一行的第一列的状态子集已确定,例如记为I,则可以求出Ia和Ib
(3)检查Ia和Ib是否已在表的第一列中出现,把未曾出现者填入到后面空行的第一列位置上。
(4)对未重复Ia 、Ib的新行重复上述过程(2)、(3),直到所有第二列和第三列的子集全部在第一列中出现
DFA 的初态位该表第一行第一列的状态
DFA 的终态为含有原 NFA 的终态的状态子集
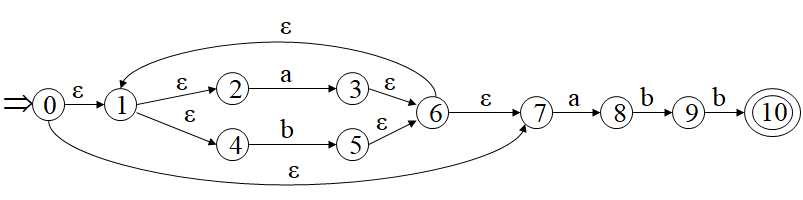
| I | Ia | Ib | S | a | b |
|---|---|---|---|---|---|
| {0,1,2,4,7} | {1,2,3,4,6,7,8} | {1,2,4,5,6,7} | 0 | 1 | 2 |
| {1,2,3,4,6,7,8} | {1,2,3,4,6,7,8} | {1,2,4,5,6,7,9} | 1 | 1 | 3 |
| {1,2,4,5,6,7} | {1,2,3,4,6,7,8} | {1,2,4,5,6,7} | 2 | 1 | 2 |
| {1,2,4,5,6,7,9} | {1,2,3,4,6,7,8} | {1,2,4,5,6,7,10} | 3 | 1 | 4 |
| {1,2,4,5,6,7,10} | {1,2,3,4,6,7,8} | {1,2,4,5,6,7} | 4 | 1 | 2 |
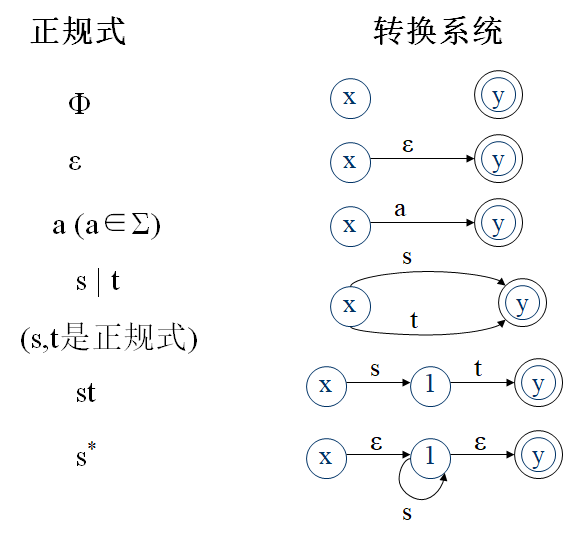
对于任一输入符号串,从文法的识别符号出发,根据当前的输入符号,唯一的确定一个产生式,用产生式的右部的符号串替代相应的非终结符往下推导,或构造一棵语法树。若能推导出输入串或构造语法树成功则输入串是句子,否则不是。
理解
FIRST(A)是以A开始符的集合,A的所有可能推导的开头终结符或者是ε
例子
后面跟的不是非终结符
1 |
|
后面跟非终结符(一)
1 |
|
后面跟的非终结符(二)
1 |
|
后面跟的非终结符(三)
1 | ... |
构造文法G的每一文法符号X,X ∈ (VT∪VN)
如果 X 是终结符号,那么FIRST(X)={X}
如果 X 是非终结符号,且 X -> Y1Y2Y3…Yk 是产生式
如果X是非终结符号,且有X->ε,那么ε在FIRST(X)中
理解
Follow(A)为非终结符A后跟符号的集合,Follow(A)是所有句型中出现在紧接A之后的终结符或’#‘
求解规则
将标记 # 放到 FOLLOW(S) 中
按照下面两个规则不断迭代,直到所有的 FOLLOW 集合都不再增长为止
理解求解规则
将标记 # 放到 FOLLOW(S) 中
形如A -> αBβ
(α可以是终结符或者非终结符或者直接为空,β可以是终结符或者非终结符,注意β不能为空,B后面要有东西)
比如
1 | A->B |
那么 FOLLOW(A) 中的所有符号都加入到 FOLLOW(B) 中
例子一
注意:[if] 是一个终结符,同理[b] [other] [else] [then]
1 | G(S):S->IETSP|O |
| First | Follow |
|---|---|
| First(S)={if,other} | Follow(S)={井号 ,else} |
| First(I)={if} | Follow(I)={b} |
| First(E)={b} | Follow(E)={then} |
| First(O)={other} | Follow(O)={else,井号} |
| First(L)={else} | Follow(L)={if,other} |
| First(P)={else,ε} | Follow(P)={else,井号} |
| First(T)={then} | Follow(T)={if,other} |
理解
解决方法:提取左公因子
若文法中存在形如:
1 | A->ay|ab |
(1)直接左递归
1 | A->AB, A∈Vn,B属于V* |
方法:左递归变右递归
1 | P->β1P'|β2P'|…|βnP' |
例:给定文法G(S):
1 | E->E+T|T |
消除其直接左递归G(E):
1 | E->TE' |
(2)间接左递归
1 | A->Bb |
(这里第二种情况注意,因为是左递归,所以看得就是第一个字符,一定要跟这个类型一样的A->B…. 以及B->A…. 这种才是左递归,如果A->B…. ,B->aA…, 这种就不是左递归了,因为样式不同,请注意)
同样消除左递归的方法:
如果是间接左递归,则先转换成直接左递归:
例子:
1 | A->Bb | c |
将B->Aa代入到另一个式子:
1 | A->Aab | c |
转换
1 | A->cM |
已知文法G[S]:
1 | S→aH |
构造其递归下降分析程序
1 | PROCEDURE S |
构造预测分析表的步骤
算符优先分析法(Operator Precedence Parse)是仿效四则运算的计算过程而构造的一种语法分析方法。算符优先分析法的关键是比较两个相继出现的终结符的优先级而决定应采取的动作。
优点:简单,有效,适合表达式的分析。
缺点:只适合于算符优先文法,是一个不大的文法类。
(算符优先三种关系的符号,中间都有圆点)
FIRSTVT
找FIRSTVT的三条规则:如果要找A的FIRSTVT,A的候选式中出现:
LASTVT
找LASTVT的三条规则:如果要找A的LASTVT,A的候选式中出现:
a=b 关系
可直接查看产生式的右部,对如下形式的产生式
A->…ab…
A->…aBb…
则有 a=b 成立
a<b 关系
对于所给表达式文法中终结符 a 在前,非终结符 B 在后的所有相邻符号对,有 b 属于FIRSTVT(B),则 a<b 成立
a<FIRSTVT()
a>b 关系
对于所给表达式文法中非终结 B 在前,终结符 a 在后的所有相邻符号对,有 a 属于LASTVT(B),则 b>a 成立
LASTVT()>a
1 | 已知文法: |
FIRSTVT和LASTVT的构造
FIRSTVT(S)={a, ^, (}
FIRSTVT(T)={a, ^, (, 逗号}
LASTVT(S)={a, ^, )}
LASTVT(T)={a, ^, ), 逗号}
构造算法优先关系表
引进产生式 S’ -> #S#
找 a=b 关系
S -> (T) 有 (=)
S’ -> #E# 有 #=#
找 a<b 关系
S -> (T) 有 ( < FIRSTVT(T)={a, ^, (, 逗号}
T -> T,S 有 逗号 < FIRSTVT(S)={a, ^, (}
S’ -> #S# 有 # < FIRSTVT(S)={a, ^, (}
找 a>b 关系
S -> (T) 有 LASTVT(T)={a, ^, ), 逗号} > )
T -> T,S 有 LASTVT(T)={a, ^, ), 逗号} > 逗号
S’ -> #S# 有 LASTVT(S)={a, ^, )} > #
结果如下表
| a | ^ | ( | ) | , | # | |
|---|---|---|---|---|---|---|
| a | > | > | > | |||
| ^ | > | > | > | |||
| ( | < | < | < | = | < | |
| ) | > | > | > | |||
| , | < | < | < | > | > | |
| # | < | < | < | = |
规约过程
(a, a)#
| 步骤 | 符号栈 | 优先关系 | 剩余输入串 | 动作 |
|---|---|---|---|---|
| (1) | # | < | (a,a)# | 移进 |
| (2) | #( | < | a,a)# | 移进 |
| (3) | #(a | > | ,a)# | 规约(S -> a) |
| (4) | #(S | < | ,a)# | 移进(忽略S进行比较) |
| (5) | #(S, | < | a)# | 移进 |
| (6) | #(S,a | > | )# | 规约(S -> a) |
| (7) | #(S,S | > | )# | 规约(T -> T,S) |
| (8) | #(S | = | )# | 移进(未分析完成,继续) |
| (9) | #(S) | > | # | 规约(S -> (T)) |
| (10) | #S | = | # | 分析成功 |
短语
令文法G,开始符号为S,αβδ是G的句型(即S=>αβδ),如果S=>αAδ且A=>β,则称β是句型αβδ相对于非终结符A的短语。
(非终结符不断推导,只剩不能推导的符号)
直接短语
如短语中有A=>β,则称β是句型相对于规则A→β的直接短语。
(非终结符一次推导,只剩不能推导的符号,才能称为直接短语)
句柄
一个句型的最左直接短语称为该句型的句柄。
素短语
文法G某句型的一个短语是素短语,当且仅当它至少含有一个终结符,且除它自身之外不再含更小的素短语。
最左素短语
在具有多个素短语的句型中处于最左边的那个素短语
做法:画语法树
注:由于 # 的转义问题,有些地方用 井 代替
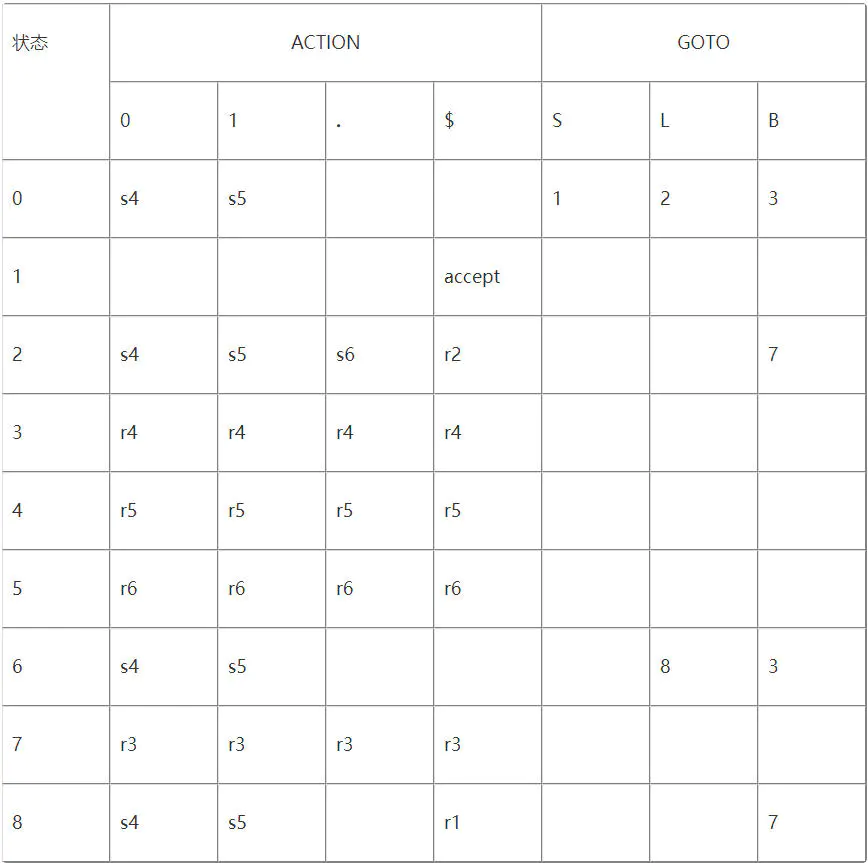
LR分析表的结构如上,其分为两个部分Action、Goto
Action
两个参数状态i,终结符号a(s(i)代表第i个状态,r(i)代表第i条表达式)
Goto
Goto[i,A]=j
移进项目。原点为终结符的项目,比如 E->a·bB
规约项目。圆点在产生式右部最后的项目,比如 A->d·
待约项目。圆点后为非终结符的项目,比如 E->b·B
接受项目。规约项目为 S’->S·,表示已分析成功
项目集非法情况:
若不存在上述情况,称文法为 LR(0) 文法
1 | 若有定义二进制数的方法如下: |
因为本题入口有两个—— E -> aA 和 E -> bB,所以需要构造额外的产生式 S’->E
扩充
1 | (0) S'->E |
项目
接下来求文法的项目,就是给每个规则加一个点以后然后挪位置,挪一个位置就得到一个项目,如下
1 | 1.S'->·E 2.S'->E· 3.E->·aA 4.E->a·A 5.E->aA· 6.A->·cA |
项目集规范族
把有 S’ 的项目而且点在最左边的项目作为状态 I0 的核,放在开头。然后看这个点后面的非终结符,是个 E,接下来就去项目中找左部是 E 的而且点在最左边开头位置的项目,列在核的下面,这就是状态 I0
接下来还是先看核里面点后的这个非终结符E,输入E(你可以理解为在箭弧上标了个E),把点向后移一位,得到 S’->E·,这其实是得到了一个新的状态的核。当然另外两个也一样,输入点后面的符号,比如输入a得到 E->a·A 为核的新状态,输入b得到 E->b·B 为核的新状态。得到新状态的核了,就是看核的点后面的非终结符,找以这个非终结符为左部的点在最左边的项目。如果点后面没有东西就不用找了。
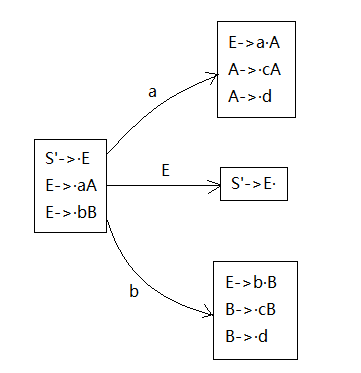
接下来就是重复上面的工作,从每一个新状态出发,逐个输入每个项目点后面的符号,就是后移一位,又分别作为新的状态的核然后根据核找下面的同状态里的项目。找到找不动为止。
(项目集标号(I0,I1…)最好按照广度优先搜索的方式标号)
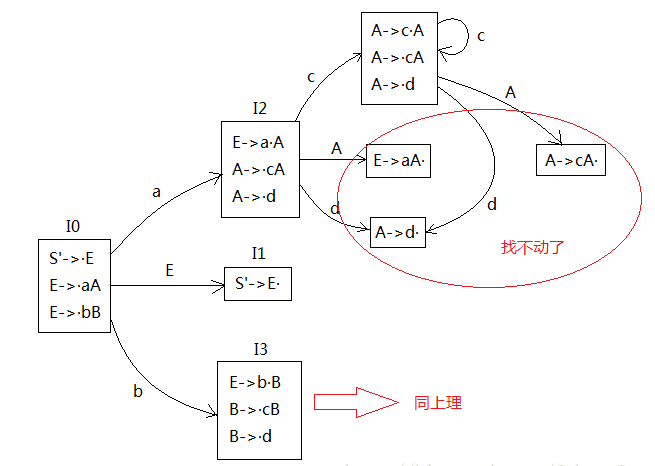
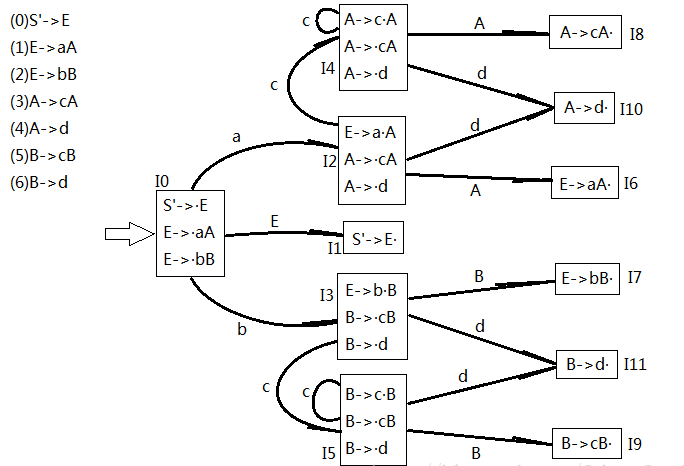
分析表
先写好 ACTION 和 GOTO 两个列标题,然后在 ACTION 下面写一排文法的所有的终结符,别忘了还有 #,GOTO下面写文法中除了 S’ 以外的所有的非终结符。

找项目集规范族有 S’->A· 这种形状的那个状态 Ik,就是第 k 个状态,则把分析表第 k 行的 # 列标上 acc
(例子中,状态 I1 里面有 S’->E·,所以 acc 在第1行)
按顺序(一般是按状态序号顺序)分析状态的项目和GOTO函数,主要就是看每个项目的 · 后面的符号
有的项目的点是在最后。先看这个项目所在的状态,再看点前面的规则是文法里面的第几个规则,比如说状态 I10 的 A->d· 里面的 A->d 就是文法的第 4 条规则,那就在分析表的第 10 行所有的终结符列包括 # 列写上 r4,就是 ACTION 列的一行写满。即状态 Ik 的项目来自于文法的第 j 条规则,则分析表的第 k 行都是 rj。
结果如下:
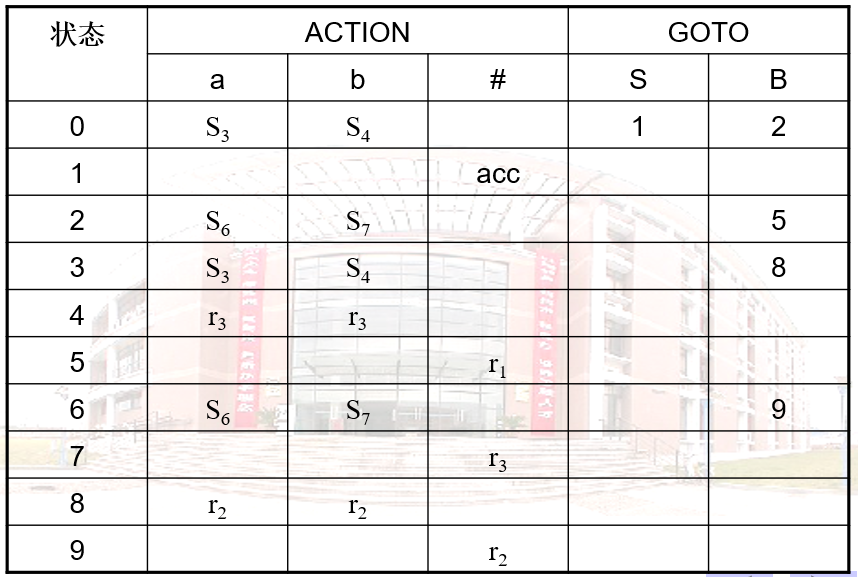
分析过程
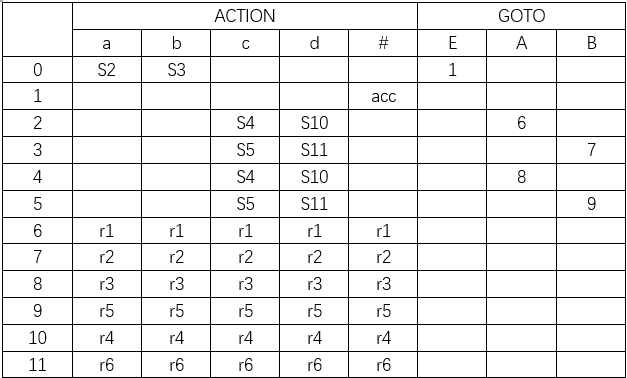
分析bccd
符号栈中是#,输入符号串就是给定的要分析的串,状态栈因为从0开始,所以状态栈直接填0
当前输入串bccd#,即将输入b,看状态栈顶是0,看分析表第0行第b列是S3。把角标3压状态栈,b压符号栈,输入串少一个。
当前为ccd#,即将压c,状态栈顶为3,看分析表第3行第c列是S5,5和c分别压栈。
当前为cd#,即将压c,状态栈顶为5,看分析表第5行第c列是S5,5和c分别压栈。
当前为d#,即将压d,状态栈顶为5,看分析表第5行第d列是S11,11和d分别压栈。
当前为#,即将压#,状态栈顶为11,看分析表第11行第#列是r6。看文法的第6条规则,把符号栈顶归约为B,状态栈顶11弹出。然后再看状态栈顶5和符号栈顶B,GOTO表第5行第B列是9,记得在分析过程这一步的GOTO写9,然后把9压状态栈。这里要分清栈操作的先后顺序。
当前为#,即将压#,状态栈顶为9,看分析表第9行第#列是r5,看文法的第5条规则,cB 归约成 B ,状态栈顶5和9弹出,然后找GOTO表把新状态9压栈。
重复上面的操作。
最后一步,状态栈顶为1,即将压#,分析表第1行第#列为acc,至此分析结束,bccd是该文法的产生式。
| 步骤 | 状态栈 | 符号栈 | 输入串 | ACTION | GOTO |
|---|---|---|---|---|---|
| 1 | 0 | # | bccd# | S3 | |
| 2 | 03 | #b | ccd# | S5 | |
| 3 | 035 | #bc | cd# | S5 | |
| 4 | 0355 | #bcc | d# | S11 | |
| 5 | 0355(11) | #bccd | # | r6 | 9 |
| 6 | 03559 | #bccB | # | r5 | 9 |
| 7 | 0359 | #bcB | # | r5 | 7 |
| 8 | 037 | #bB | # | r2 | 1 |
| 9 | 01 | #E | # | acc |
SLR分析表的构造步骤
考察算术表达式文法的拓广文法:
1 | (0) S’ -> E (1) E -> E+T (2) E -> T (3) T -> T*F |
前三步同 LR(0) 文法,,得到如下:
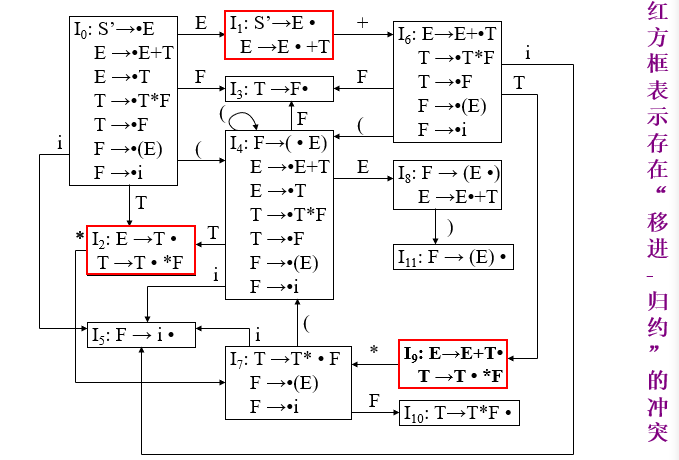
红框处存在移进-规约冲突(比如I1中 S’->E· 是规约项目,E->E·+T是移进项目)
首先找出所有点在最后的,即规约项目:
1 | S’ -> E· |
求相关follow集(圆点·不算进去)
follow规则
将标记 # 放到 FOLLOW(S) 中
按照下面两个规则不断迭代,直到所有的 FOLLOW 集合都不再增长为止
求得:
1 | FOLLOW(S')={#} |
分析表构造规则
步骤
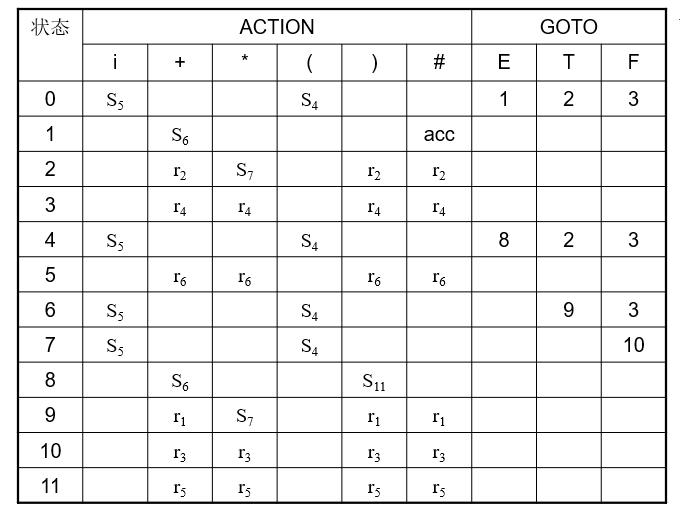
可以看到,SLR(1) 分析表的构造和 LR(0) 分析表的构造类似,但有两处不同:
解决 SLR(1) 不能解决的冲突
例子:
1 | (0) S’ -> S (1) S -> BB (2) B -> aB (3) B -> b |
规则
1 | 构造闭包函数: |
步骤
首先构造 I0。把 [S’ -> •S, 井] 放入,找出所有左部是 S 的而且点 • 在最左边开头位置的项目,有 [S -> •BB],而 FIRST(井)={井},所以为 [S -> •BB, 井]
再找出所有左部是 B 的而且点 • 在最左边开头位置的项目,有 [B -> •aB] 和 [B -> •b],而 FIRST(B井)={a,b},所以为 [B -> •aB, a/b] 和 [B -> •b, a/b]
I0为:
接下来先看核里面点后的这个非终结符E,输入S(你可以理解为在箭弧上标了个 S),把点向后移一位,得到 [S’ -> S·,#],这其实是得到了一个新的状态的核。当然另外两个也一样,输入点后面的符号,比如输入 a 得到 [B->a·B, a/b] 为核的新状态,输入b得到 [E->b· ,a/b] 为核的新状态。得到新状态的核,继续按照构造闭包函数规则构造,结果如下:
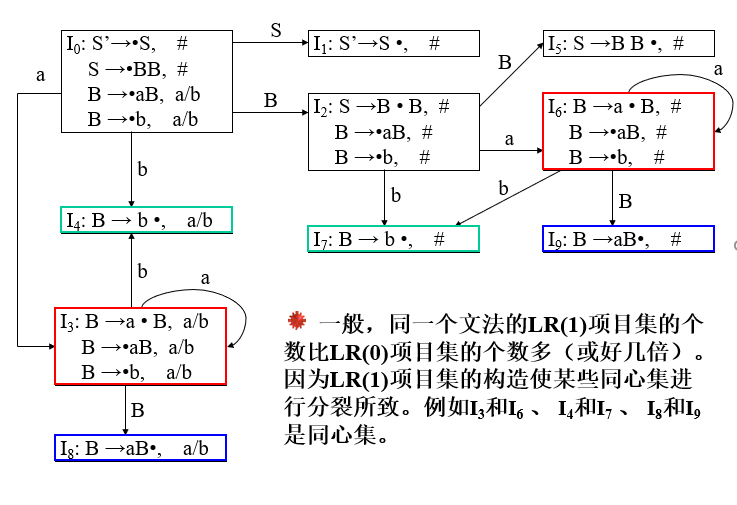
规则
假定 C={I0, I1,……, In},令每个项目集 Ik 的下标 k 为分析器的一个状态。令那个含有项目 [S’→•S, #] 的 Ik 的下标 k 为初态,函数 ACTION 表和 GOTO 表可按如下方法构造:
步骤
状态0,接受 a 到达3状态,填 S3;接受 b 到达4状态,填 S4;
接受 S,B到达1,2状态,在 GOTO 分别填1,2
状态1,为 [S’→S •, #] ,# 列填 acc
状态2,接受 a 到达6状态,填 S6;接受 b 到达7状态,填 S7;接受 B 到达5状态,在 GOTO 填5
状态3,接受 a 到达3状态,填 S3;接受 b 到达4状态,填 S4;接受 B 到达8状态,在 GOTO 填8
状态4,使用规则2,用产生式 B -> b 进行规约,a、b 列填 r3
状态5,使用规则2,用产生式 S -> BB 进行规约,# 列填 r1
按规则填完,结果如图:
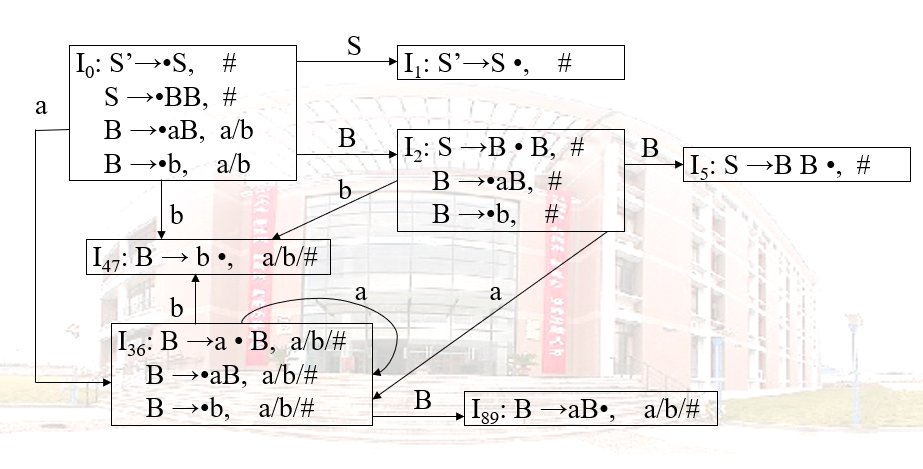
基本思想:
首先构造 LR(1)项目集族,若不存在冲突,就把同心集合并
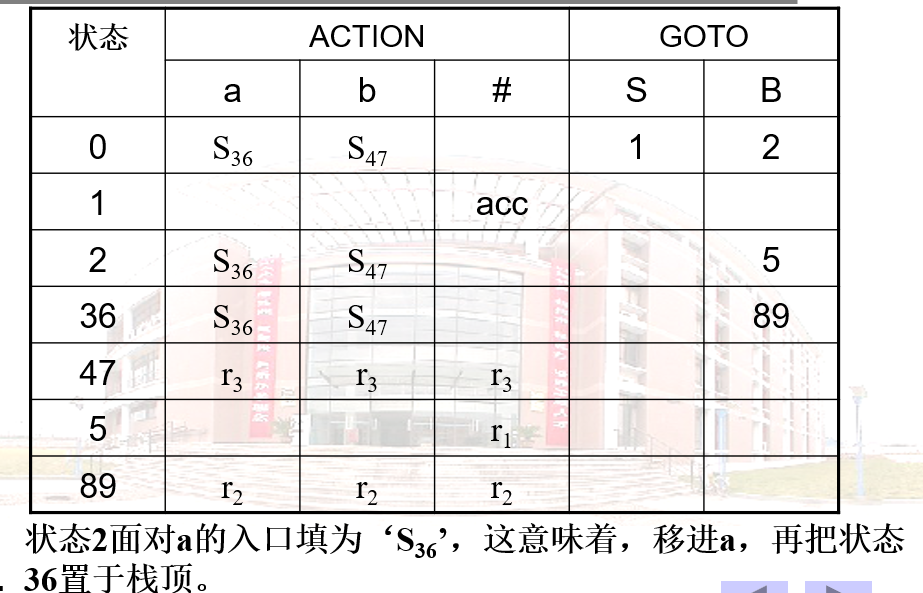
分析表的方法同 LR(1)
波兰表示是一种既不须考虑优先关系、又不用括号的一种表示表达式的方法(前缀式)。
逆波兰表示形式,称为后缀式,即运算符在后。
求法:
对单目运算符,直接将其放到变量后面,然后按照运算优先顺序,对双目运算符进行转换
例:
1 | a+b -> ab+ |
三元式由三个部分组成:
X:=A+B*C 可表示成
| OP | ARG1 | ARG2 | |
|---|---|---|---|
| (1) | * | B | C |
| (2) | + | A | (1) |
| (3) | := | X | (2) |
为便于代码优化处理,常常不直接使用三元式,而是另设一张指示器表(称为间接码表),它将按运算的先后顺序列出的有关三元式在三元表中的位置。即,用一张间接码表辅以三元式表来表示中间代码,这种表示法称为间接三元式。
例如 语句 X:=(A+B)*C; Y:=D ↑(A+B)的间接三元式表示
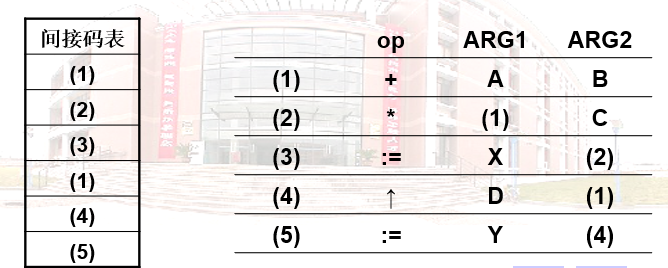
注意:在间接三元式下,相同的三元式,无需重复填进三元式表中,如上例中的(A+B)。但三元式和四元式需要重复填
四元式由四个部分组成:
ARG1、ARG2、RESULT有时指用户自定义的变量,有时指编译程序引进的临时变量。如果OP是一个算术或逻辑算符,则RESULT总是一个新引进的临时变量,用来存放运算结果
例:
A:=-B*(C+D)的四元式表示:
| OP | ARG1 | ARG2 | RESULT | 注释 | |
|---|---|---|---|---|---|
| (1) | @ | B | - | T1 | T1是临时变量 |
| (2) | + | C | D | T2 | T2是临时变量 |
| (3) | * | T1 | T2 | T3 | T3是临时变量 |
| (4) | := | T3 | - | A | 赋值运算 |
凡只需一个运算量的算符一律规定使用ARG1
如同三元式一样,四元式出现的顺序与表达式计值的顺序是一样的
写出 -A*(B+C)-D*(B+C) 的后缀式、三元式、间接三元式、四元式
后缀式:
1 | A@BC+*DBC+*- |
三元式:
| OP | ARG1 | ARG2 | |
|---|---|---|---|
| (1) | @ | A | - |
| (2) | + | B | C |
| (3) | * | (1) | (2) |
| (4) | + | B | C |
| (5) | * | D | (4) |
| (6) | - | (3) | (5) |
间接三元式:
1 | 三元式表 |
四元式:
1 | (1) (@,A,-,T1) |
写出 A+B*(C-D)+E/(C-D)**N 的后缀式、三元式、间接三元式、四元式
后缀式:
1 | ABCD-*+ECD-N**/+ |
三元式:
1 | (1) (-,C,D) |
间接三元式:
1 | 三元式表 |
四元式:
1 | (1) (-,C,D,T1) |
对作为转换条件的布尔式E,可以把它翻译成仅含下述三种形式的四元式序列:
写出语句If ﹁A ∨ B<C ∧ D<E then X:= Y+Z else X:=Y*Z 的四元式序列
1 | 100 (jnz,A,-,102) |
1 | 写出四元式序列 |
将下列的IF语句翻译成四元式序列
1 | if A and B and (C > D) |
1 | 100 (jnz,A,-,102) |
将下列的FOR语句翻译成四元式序列
1 | for i := a + b * 2 to c + d + 10 do |
1 | 100 (*,b,2,T1) |
预计两题
一题
预计两题
Things You Should Never Do, Part I – Joel on Software
这是国外的老程序员 Joel Spolsky 在2000年写的文章。
更详尽的带图表的分析:
Why You Should (Almost) Never Rewrite Code – A Graphical Guide
Avram Joel Spolsky 生于1965年,他是一位软件工程师和作家。他是“Joel on Software”博客的作者。他从1991年到1994年间担任 Microsoft Excel 团队的项目经理。在2000年,他创立了 Fog Creek 软件并开启了“Joel on Software”博客。2008年,他和Jeff Atwood一起启动了如今极为成功的 Stack Overflow 程序员问答网站。他们用Stack Exchange软件产品作为Stack Overflow的引擎。现如今Stack Exchange网络已经包含了91个站点。
他在这篇文章的论点来源于一个简单的事实:
It’s harder to read code than to write it.
写代码容易,读代码难。
在开头,他批评网景公司犯了的最严重的战略错误——他们决定从头开始重写代码
1 | 由于网景当时的极度成功,公司规模扩展很快,为了应对开发的需求而收购了一家大型软件开发公司。但这家被收购公司的高层以及开发人员做了一系列愚蠢决定,包括使用当时如麻花一般的 C++ 代替 C,削减支持平台,优先发布 Windows 版本浏览器等,最后造成了新版本发布遥遥无期,程序质量不高等一系列问题,失去了对其他浏览器(包括IE)功能上和性能上的绝对优势,而结果就是被用户抛弃。 |
作者的观点主要有:
上面三个中的任何一个都可能致命,但是所有三个问题肯定都是致命的,产品的竞争力可能永远不会恢复。
如果公司的项目或产品代码混乱到无法再加入新功能或提升性能,跟时代严重脱节怎么办,那么应用以上原则,这时候既然这个项目已经快死了,那么放到新项目里重写显然是最合理的选择。
同样是 Joel Spolsky 在2000年写的文章。
The Joel Test: 12 Steps to Better Code
他用这十二条来评估软件团队的质量,大多数软件组织的运行得分为2或3,像 Microsoft 这样的公司的得分为12。
1.您是否使用源代码管理?
如果您没有源代码控制,那么您将不得不尝试使程序员们一起工作。程序员无法知道其他人做了什么。错误不能轻易回滚。
在源代码层面使其易于管理、维护,同时降低核心技术泄密风险。
2.你们可以把整个系统从源码到CD映像文件一步建成吗?
这句话问的问题是:从你们最新的源码开始到建立起能够交出去的最后文件,你们有多少步骤要做? 一个好的团队应该有一个批处理程序一步便可将所有的工作做完,像把源文件提取出来,跟据不同的语言版本要求(英文版,中文版),和各种编译开关(#ifdef)进行编译,联接成可执行文件,标上版本号,打包成CD映像文件或直接送到网站上去,等等等等。
3.您是否进行日常构建?
在微软软件开发中,每日构建是最重要的过程之一,被称为微软产品开发的“心跳”。简单来看,每天构建系统将整个产品解决方案完整构建一遍,生成的目标文件和安装文件被放置在一个共享位置。接着,安装文件被自动部署到release server上,随后可以自动运行BVT(build verification test),并将所有结果寄送每个team member的信箱。
4.您是否有 bug 数据库?
如果您正在开发代码,即使是一个团队,也没有列出代码中所有已知错误的有组织的数据库,那么您将交付低质量的代码。
5.在编写新代码之前,您是否修复了 bug?
要立即修复 bug 的原因之一:因为它花费的时间更少。还有另一个原因,这与以下事实有关:预测编写新代码要比修复现有 bug 要花多长时间。例如,如果我要求您预测编写代码以对列表进行排序所需的时间,那么您可以给我一个很好的估计。但是,如果我问你如何预测这将需要多长时间来修复 bug:如果安装Internet Explorer 5.5您的代码不工作,你甚至无法猜测的,因为你不知道(定义)是什么导致 bug。跟踪可能需要3天,或者可能需要2分钟。
这意味着如果您的日程安排中有许多尚待修复的 bug,则该日程安排是不可靠的。但是,如果您已经解决了所有已知的 bug,而剩下的只是新代码,那么您的日程安排将更加准确。
将 bug 计数保持为零的另一个很棒的事情是,您可以更快地响应竞争。一些程序员认为这是使产品随时准备就的准备*。然后,如果您的竞争对手推出了一种吸引用户的杀手级新功能,则您可以实施该功能并当场发货,而无需修复大量累积的 bug。
6.您有最新的时间表吗?
这使我们按计划进行。如果您的代码对企业至关重要,则有很多原因说明知道何时完成代码对企业很重要。
制定时间表的另一个关键之处在于,它迫使您决定要执行的功能,然后迫使您选择最不重要的功能并将其剪切掉,而不是陷入特征成熟度(又称范围蠕动)。
7.您有写软件规格说明书(SPEC)吗?
在产品的前期设计过程中,如果你发现了一些问题,你可以轻易地在说明书里该几行字就行了。一旦进入了写程序的阶段,解决问题的代价就要高得多了。
没有产品开发详细说明书就开始写程序,往往会导致程序写的乱七八糟,而且左拖右拖不能交付使用。
不论采用以上哪种方法,道理只有一个:在没有产品开发详细说明书之前,决不可写程序。
8.程序员有安静的工作条件吗?
通过为知识工作者提供空间,安静和私密性,可以广泛地记录生产率的提高。
9.您是否使用金钱可以买到的最好的工具?
要给予程序员尽可能好的条件
10.您有测试员吗?
需要有测试员来检测产品的漏洞
11.新候选人在面试中是否写代码?
通过写代码了解程序员的能力,而不是看似漂亮的简历和问几个简单的问题(如CreateDialog()和DialogBox()有什么区别?这种问题,查一下帮助文件就知道了)
12.您是否进行走廊可用性测试(hallway usability testing)?
也就是随便抓一个人来,进行测试。
走廊实用性测试对于企业产品测试来讲提供的反馈比招募来做测试得出的结论要好很多,而且很多时候是完全相反的结论。
但现在很多企业都不做走廊测试了,而改用poll这种电子方式在Social Media发布,让用户选择。原因是走廊测试这种方法的效率不高。
The Development Abstraction Layer – Joel on Software
对于软件公司来说,管理的第一要务需要为程序员创造抽象。
我认为Joel的看法是尽量不能让程序员分心,让大家能够各司其职,每个人都能拥有良好的工作环境。
创造抽象的目的就是让程序员专心于开发,发挥其长处,最终创造更好的软件,使用户受益。
Good Software Takes Ten Years. Get Used To it. – Joel on Software
Joel 认为推出一个好的软件需要很长时间,也就是十年规则。
不理解十年规则会导致关键的业务错误
Get Big Fast 综合征(前期啥也别想,把用户量干上去就行了,不要在乎利润这种东西)
这种”从构建到翻转”的心态、公司庞大的超员和超支,以及每十分钟提高一次风投的需要,使得软件在10年内无法开发。
炒作综合征(the Overhype syndrome)
当你发布软件1.0版本时,需要保持冷静,而不是大肆炒作
相信互联网时间(Internet Time)
加快了版本升级速度,减少升级周期。
但是软件的创建速度没有加快,只是发布频率更高。
完成软件后,将不会再有收入
“准备好了我们就发货” 综合症
软件需要10年才能编写,但如果你10年不发布,企业就不可能生存下去
你必须提前发布不完整的版本,使他们相信你的版本1.0是有希望的——但不要夸大其言,因为它们不是那么好,不管你有多聪明。
过于频繁的升级(Too-frequent upgrades)
用户并不总是需要最新和最好的软件版本
良好的软件必须使用真实世界的数据来处理它在现实世界中可能遇到的例外。乔尔对”好软件”的定义是已经学会处理的软件。因此,可以在广大的情况下,为广大人民群众使用。
(说实话,拿 Lotus Notes当正面教材,在现在看来,有点好笑。高昂的价格,落后封闭的技术,维护和升级困难,反人类的交互设计使得其不断衰落)
该文章写于2001年,作者写这篇文章也是对2000年的互联网泡沫的思考。
互联网泡沫开始应该是从1999年开始的,那时候美国处于一个相对低息的周期,只有4%左右的利率。流动性开始涌入以互联网企业为代表的,新兴经济体,特别是在GDP增长,以及股市攀升带来的纸上富贵错觉影响下,拉动的消费增长,极大的增加的企业营收,越来越多的企业愿意在这些互联网公司身上投放网络广告。网络广告,也就是横幅banner,是当时互联网企业唯一的能够盈利的商业模式。新经济概念+营收增长+新商业模式故事带来的预期增长(其实就是网络销售 B2C B2B),形成戴维斯双击错觉+正循环效应。让所有的人都心潮澎湃,nasdq指数的斜率陡然攀升,互联网大泡沫开始形成。很多企业在 ipo 的时候,就享受2-5倍的股价攀升,分析师、投资者、企业家、风投、银行全部都陷入狂热的情绪当中,everybody is winner,no loser.
那时候格林斯潘,还是美联储主席,预感到经济过热,和足够低的失业率空间,给了鹰派足够的多的话语权,美国开始进入一个加息周期,利率4%逐渐攀升到6%。
流动性的减少,带来了企业净利润的削弱,广告投放的减少,外加那些不挣钱的 B2B B2C业务,还有并购业务的繁荣,疯狂蚕食互联网企业的现金流,聪明的投资者开始意识到,这是一场不可持续的繁荣,已经有人在开始撤离,纳斯达克从最高点的5048.62开始逐渐回落,但是市场总体的情绪,并没有意识到这大周期的逆转点,抄底才是主旋律。
当然,那时候市场还有些别的新闻,为股市的下跌做出合理化的解释,最著名的莫过于微软公司在反垄断诉讼中的失败,被贴上的垄断的标签,差点面临被拆分的命运。
《巴伦周刊》上的一篇报道基于207家互联网公司的研究报告指出,将会有51家网络公司,现金流面临枯竭,而且股价下行+高管套现+投资风险厌恶上升+市场资金缩减+再融资市场的冷却,多重效应叠加下,这些公司的再融资问题无法得到解决,最终将会面临行业的大洗牌,破产加重组。
这篇报道引发了市场了恐慌,所有人才从如梦如幻的错觉中清醒过来,疯狂抛售自己手中的网络股票,市场在挤兑的浪潮下,纳斯达克指数在一年多的时间,跌到了最低点1114.11。
股指的下跌持续了2年,中途加上9·11事件带来影响,整个纳斯达克市值跌掉了5万亿美元,指数只有巅峰时期的四分之一不到,是美国历史上最大的金融泡沫之一,纳斯达克花了15年才恢复到2000年之前的水平。
再看2000年:泡沫破灭时的公司存亡 - 知乎 (zhihu.com)
大多数的公司并没有像当时的亚马逊、Ebay或者谷歌一样把金钱投入到技术和产品本身的建设,而仅仅停留在打广告拉新推广这种烧钱的模式中,占领市场全靠昂贵的广告和并购。
决定一家公司未来发展最重要的因素是公司优质可持续的发展模式,这也是其抵御危机的绝对筹码。只有一个好的创意确实有可能拿到大笔融资,但是如果没有持续的盈利能力,公司做大也只是一场泡沫,危机来临之时也会迅速坍塌
Meet Minimum Requirements: Anything More is Too Much - The Neal Whitten Group
作者 Neal Whitten 认为对于一个项目,首要的是满足最低要求,提交仅包含基本功能的项目计划,并针对非必要功能制定”壁橱计划”。
项目最常见的问题之一是承担了太多的工作——试图超越要求而不是满足最低要求。这造成了过多的不良影响,包括延迟交货、预算超支、士气低落和质量差。试图把俗话说的10磅塞进一个5磅重的袋子里是司空见惯的事。
“满足最低要求”意味着给客户成功所需的条件:但不提供必要的功能。其他功能是未来的发布和未来的商业机会。重要的是要赢得可靠履行客户承诺的声誉,然后被信任在常规的、可预测的基础上继续升级。这是一个很好的业务。
大多数人习惯于认为”满足最低要求”是没有刺激性和非竞争性的。作者认为情况正好相反。刻意实践符合最低要求,有助于组织或公司率先进入市场,从客户那里赢得越来越多的信誉,并有力地为企业创造新的商业机会摆出姿态。采用满足最低要求的概念可以为组织设置卓越的绩效。
纪录片《Code Rush》
节选一些读后感
看到CSDN上有不少人推荐,就看了这部纪录片。
与开始想象的不一样,这部纪录片的重点不是放在微软和网景的历史纠葛上,不是像很多描写硅谷商战的电影那样为故事添油加醋,非要展现出一个个令人血脉贲张、扣人心弦的情节不可,而是把重点放在描述那个历史背景下网景程序员的日常生活。
我也是程序员,在一个普通的IT公司上班,薪水待遇还算OK,但是工作压力比较大,项目紧的时候加班也是家常便饭。相信大部分程序员兄弟也是这种生活状态。我有时会在心里自嘲,天下有千万种职业,怎么我就选择做了苦逼的程序员呢?好像当初大学选了个计算系专业,这样稀里糊涂地就过来了。再看看人家美国小孩,从小就喜欢坐在电脑前写程序,16岁的时候已经为Mozilla的开源项目工作多年了,高中毕业之后顺理成章地来到硅谷工作。人家才是选择自己最喜欢和最擅长的事情作为职业,这是一件多么幸福的事。可惜成长在中国应试教育下面的大部分年轻人就没有这么好的运气了。
面对工作的重重压力,公司业绩的下滑,网景的程序员们又是怎么看待程序员生活的呢?有的人为自己订下约定,35岁之后就结束苦逼的程序员生涯,转行做别的;有的人在公司卖给AOL之后,趁着股价坚挺,赚了一笔,套现走人;有的人(公司领导)选择继续留在公司;还有的人选择去新的公司,继续追求自己的开源和技术理想。不管选择的道路怎样,正如片中所说,程序员们都要付出比很多行业更多的工作时间,把青春中最美好的时光花在了电脑前面,而不是与亲人朋友相处上。即使是创业成功而一夜暴富的人,他付出的代价也是常人难以想见的,而不了解的人往往只看到了表面的光鲜。
人们喜欢津津乐道乔布斯、盖茨们的成功,却忽视了在这些IT巨头背后,一些挣扎着与他们抗争的小公司。即使技术强如网景,也需要为商业上的失败买单。程序员们常常会有一种分裂的感觉:在计算机的世界里,他们是无所不能的上帝;而在其他方面,例如商业策略,他们又根本无能为力;于是会有瞬间从天堂跌落谷底的感觉,因为最出色的技术也并不能保证商业上的成功。即使好不容易杀出一条血路,也可能马上就被微软腾讯这样的巨头像捏死一只蚂蚁一样捏死。
谈了这么多程序员生活的艰辛,其实做一个程序员也有好的地方:有机会改变世界,生活中充满有趣的刺激和挑战,还有机会一夜暴富。很多程序员都是一个梦想家,是梦想给予他们力量度过苦与乐并存的生活。
作者: 阮一峰
这是一部关于Netscape公司的纪录片。
如果你不知道这家伟大的公司,那么我告诉你,它是浏览器和其他许许多多东西的发明者,比如显示图片的img标签、http协议中的cookie、互联网加密协议SSL、以及javascript语言。上个世纪90年代中期,它的Netscape Communicator浏览器,曾经占据了90%的市场份额。
但是很不幸,它的对手是Microsoft。微软投入超过1亿美元,雇佣1000多个程序员,开发出了IE浏览器。更致命的是,微软将IE免费发行,并且捆绑在操作系统中。
所以,到了1998年的年初,所有人都看出来了,Netscape遇到大麻烦了。
《Code Rush》(奔腾的代码)这部纪录片,就是讲述Netscape公司在1998年的故事,摄制组整整跟拍了一年。
在其中,你可以看到两件历史性大事的第一手画面。
1998年3月31日,Netscape宣布将Netscape Communicator浏览器开源,这个新项目就叫做Mozilla。
1998年11月24日,由于股价不断创出新低,Netscape公司在绝望之中把自己以42亿美元的价格卖给了AOL。一家曾经如此辉煌的公司,就这样死了。后来的历史证明,AOL以42亿美元买来的只是一具无用的尸体。我不知道,历史上有没有比这更不合算的交易了。但是,这笔交易的好处是,AOL因此成为Mozilla项目的最大赞助者,Netscape已死,Mozilla活了下来。
Amazon上一位观众的留言标题就是”一家伟大公司之死”。
如果你对软件业感兴趣,希望了解程序员的生活,以及Mozilla项目的起源和创造它的人们,那么千万不要错过这部纪录片。
我保证这是一部过目难忘的作品。
自己学的就是计算机 自己将要从事的就是写代码 自己将要适应的就是纪录片里geek们的生活
在一个没有事情做的暑假午后看完这部10年前的纪录片 它的时代感却还是鲜活地要跳出屏幕 大起大落的网景 独断的微软巨人 呼声越来越响亮的代码开源 或许计算机硬件软件都随着摩尔定律一路向前rush着 但是计算机诞生60年来 有一些精神在代码员心里不会改变
第一是创造 不管是网景员工 或是在乡村独自为mozilla贡献代码的高中生 还是影片里在介绍美国街头变化时所透露出来的画外音 都引导人们走入程序员所构筑的平行于现实世界的虚拟空间 银行??我们有网上银行 百货大厦??我们有网购 寄达信件??用email吧 怎样将网络构筑地比拟现实甚至超越现实 一切的源头是程序员的创新和创造世界的渴望
第二是自由 有很多侧面都可以体现出程序员应该有的自由 奇怪的发型 桌上叠成金字塔的空可乐罐 混乱的工作时间 办公室里夸张的躺椅和电玩设备… 这些反映于代码 就是社区与开源 程序员所创造的一切会有同行的审评改进并最终作为全人类的财富被共享 没有太多的束缚 一切服从于本心的渴望 赚上十个亿不是程序员最大的渴望 自己写的代码运行于十亿人的电脑 才是真正值得兴奋的事情——当然能赚钱还是会很开心的>.<
第三是团队 为了在有限生命里追寻创造世界的极致 为了拥有心灵的慰藉 为了对抗巨人…我们都需要团队 每一个bug都尽力去调 每一个部分都认真写好 netscape拥有看着或许业余但是战斗力强大的团队 有术业专攻的程序员与负责的项目经理 他们有机会成功 只是现实世界变化地有些超出程序员的想象罢了…
第四是deadline 自己曾经说过追逐deadline是程序员的宿命 有了deadline 疏懒的我们才不至于躺在椅子上盯着屏幕睡成一具尸体
google谈话Eric Brechner: “AgileProject Management with Kanban” | Talksat Google_哔哩哔哩_bilibili
使用看板以最大限度地提高效率、可预测性、质量和价值
使用看板,您花在软件项目上的每一分钟都能为客户增加价值。一本书可以帮助你实现这个目标:敏捷项目管理与看板。
作者埃里克·布雷奇纳在微软的Xbox工程团队中开创了看板。现在,他告诉你如何让它为你的球队工作。
把这本书想象成”盒子里的看门人”:打开它,阅读快速启动指南,你启动和运行得很快。随着您获得经验,Brechner 揭示了正确的团队规模、估计、满足最后期限、部署组件和服务、适应或从 Scrum 或传统瀑布演变等强大技术。
在旅程的每一步,您都会找到实用的建议、有用的清单和可操作的课程。这确实是”盒子里的看板”:所有你需要提供突破的价值和质量。
看板技术:
Feature-branching workflow using Git and GitHub
参考
Git 功能分支工作流|阿特拉斯吉特教程 (atlassian.com)
使用Jenkins自动部署Springboot应用程序_哔哩哔哩_bilibili
Producing Open Source Software How to Run a Successful Free Software Project
制造开源软件 文档中心 - 文江博客 (wenjiangs.com)
作者认为大部分自由软件是失败的
开源软件开发过程中的独特问题:
当程序员对解决某个问题产生了个人兴趣之后,才能产生优秀的软件;这一点同自由软件的联系在于,大部分自由软件项目的最初动机都是始于一个人的痒痒处。
本章是关于如何将一个自由软件项目介绍给全世界
首先是寻找是否有一个现存的项目已经做了你想做的,如果有并且其已经解决了问题,那就不必重新发明轮子了。或者你脑中的计划非常特别,你肯定不会有其他人有同样的想法,那你也不妨试试看。如果没找到真正适合你的软件,可以决定开始一个新的项目。
选择一个好名字(告诉人们有关项目性质、便于记忆、不与另一个项目重名)
有一份清楚的使命陈述
声明项目是自由软件
特性和需求列表,列出一个简短的清单,说明软件支持的各种特性(如果某些特性还未完成,也可以列出,但是在旁边注明“计划中”或“建设中”),以及运行该软件所要求的系统环境。
开发状态,人们总是希望了解一个项目的状况。对新的项目,他们想知道项目的承诺和现实之间存在着多大的距离。对成熟的项目,他们想知道维护得如何,新发布的频率怎样,以及对Bug报告反应的及时性等等。
要回答这些问题,你应该建立开发状态页,列出项目的近期目标和需求(例如,需要具备某方面专长的开发人员)。开发状态页也可以列出过去发布的记录,其中包含特性清单,以便访问者了解项目是如何定义“进展”的,并根据这一定义了解项目进展的速度。
下载。应该可以以标准格式下载软件的源代码。
版本控制和Bug跟踪访问
沟通渠道
开发者指南。如果有人考虑参与项目,她会寻找开发者指南。与社会性文档相比,开发者指南通常没有很多的技巧:只需要解释开发者之间,以及与用户之间如何交互,以及如何最终完成任务。
文档(告诉读者他们所需的技术技能。清楚和完整的描述如何配置软件,并在文档的开头部分告诉用户如何运行确认安装成功的诊断测试或简单命令。提供一个普通任务的教程式的实例。标示文档中未完成的部分。)
输出和屏幕截图实例
包装主机
自由软件项目依赖于选择性捕获和信息集成的技术。对这些技术的使用越是熟练,并说服别人去使用这些技术,你的项目就越成功。
大部分开源项目至少提供了最低限度的标准工具用于管理信息:
网站
主要是一个集中将项目信息发布给公共的单向渠道。网站也可以作为其他项目工具的管理界面使用。
邮件列表
通常会是项目中最活跃的通讯手段,是“可记录的媒介”。
版本控制
让开发者可以方便地管理代码的变更,包括回复和“变更转运”。让每一个人能看到代码的变化。
Bug跟踪
使开发者可以追踪他们正在工作的内容,互相协调,以及计划发布。让每个人都能查询Bug的状况并且记录特定Bug的信息(例如重现方法)。不仅能用于对bug的追踪,而且能用于任务、发布和新特性等等。
即时聊天
一个可以快速和方便的进行讨论和问答的地方,缺点是并不总是能完整地归档。
本章尝试展示支持成功项目的共同结构。 “成功”不仅仅指的技术质量方面,而且也包含了运行健康状况和生存性。运行健康状况是指项目将新代码和新开发者吸收进来,并对到来的bug负责的持续能力。生存性是项目独立于任何单独参与者或赞助商而存在的能力—考虑一下如果项目所有的创始成员离开后项目继续运作的可能性。技术成功不难实现,但是如果没有健壮的开发者基础和社会基础,一个项目就不能处理由初始的成功带来的成长,或者有魅力个体的离开。
能将开发者绑定在一个自由软件项目中的必需组成部分,能让他们在必要时愿意作出妥协,是代码的分叉能力:也就是任何人可以使用一个拷贝并使之成为一个竞争项目的能力,被称为分叉。
慈善独裁者模型这一称号确实名副其实:最终的决定权完全取决于一个人,因为其人格和经验的力量,他被认为可以明智的运用这个权力。
Bugzilla 是一个开源的缺陷跟踪系统(Bug-Tracking System),它可以管理软件开发中缺陷的提交(new),修复(resolve),关闭(close)等整个生命周期。
Bugzilla Bug报告分类
(1)待确认的(Unconfirmed)
(2)新提交的(New)
(3)已分配的(Assigned)
(4)问题未解决的(Reopened)
(5)待返测的(Resolved)
(6)待归档的(Verified)
(7)已归档的(Closed)
(8)Bug处理意见
(9)已修改的(Fixed)
(10)不是问题(Invalid)
(11)无法修改(Wontfix)
(12)以后版本解决(Later)
(13)保留(Remind)
(14)重复(Duplicate)
(15)无法重现(Worksforme)
Bugzilla指定处理人:
(1)可以指定一个处理人
(2)如不指定处理人,则系统指定管理员为默认处理人
Bugzilla链接:
输入超链接地址,引导处理人找到与报告相关联的信息
Bugzilla概述:
(1)概述部分“Summary”的描述,应保证处理人在阅读时能够清楚提交者在进行什么操作的时候发现了什么问题。
(2)如果是通用组件部分的测试,则必须将这一通用组件对应的功能名称写入概述中,以便今后查询。
Bugzilla平台操作系统:
(1)测试应用的硬件平台(Platform),通常选择“PC”
(2)测试应用的操作系统平台(OS)
1 | git init newrepo #初始化仓库 |
每个任务由一张卡片表示。
每张可移动卡可以处于以下阶段之一:
积压、进行中的工作 (WIP) 和完成。
通常,随着工作的进行,您会转移卡片向右。
对于软件开发,我们可以有 Backlog(要求)、开发、测试、文档、完成。
优先事项。按每个阶段的卡片按重要性排序。
从你现在正在做的事情开始。
WIP limit。不要过于压倒开发人员许多任务(多任务处理)。
完成或完成规则的定义。
提前期 Lead time:任务创建和任务之间的时间完成。对客户可见。
周期时间 Cycle time:任务开始到完成。对员工可见。
燃尽图(Cumulative Flow Diagram)。是以图表展示随着时间的减少工作量的剩余情况。工作量一般以竖轴展示,时间一般以横轴展示。燃尽图对于预测何时完成工作很有用,经常被用于敏捷软件开发中,如Scrum。燃尽图也可以用于任何可测量的进度随着时间变化的项目
拉工作而不是推工作 Pull work instead of Push work
每个团队成员一种颜色
Jenkins高级用法 - Jenkinsfile 介绍及实战经验 - 晓晨Master - 博客园 (cnblogs.com)
(8条消息) 玩转Jenkins Pipeline_大宝鱼的博客-CSDN博客_jenkins pipeline
CI/CD是实现敏捷和Devops理念的一种方法。
具体而言,CI/CD 可让持续自动化和持续监控贯穿于应用的整个生命周期(从集成和测试阶段,到交付和部署)。这些关联的事务通常被统称为“CI/CD 管道”,由开发和运维团队以敏捷方式协同支持。
CI - 持续集成
持续集成(CI)是在源代码变更后自动检测、拉取、构建和(在大多数情况下)进行单元测试的过程。持续集成是启动管道的环节(尽管某些预验证 —— 通常称为 上线前检查(pre-flight checks) —— 有时会被归在持续集成之前)。
持续集成的目标是快速确保开发人员新提交的变更是好的,并且适合在代码库中进一步使用。
CD - 持续交付
持续交付(CD)通常是指整个流程链(管道),它自动监测源代码变更并通过构建、测试、打包和相关操作运行它们以生成可部署的版本,基本上没有任何人为干预。
持续交付在软件开发过程中的目标是自动化、效率、可靠性、可重复性和质量保障(通过持续测试)。
持续交付包含持续集成(自动检测源代码变更、执行构建过程、运行单元测试以验证变更),持续测试(对代码运行各种测试以保障代码质量),和(可选)持续部署(通过管道发布版本自动提供给用户)。
Pipeline,简而言之,就是一套运行于Jenkins上的工作流框架,将原本独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程编排与可视化。
Pipeline是Jenkins2.X的最核心的特性,帮助Jenkins实现从CI到CD与DevOps的转变
Pipeline是一组插件,让Jenkins可以实现持续交付管道的落地和实施。
持续交付管道(CD Pipeline)是将软件从版本控制阶段到交付给用户或客户的完整过程的自动化表现。软件的每一次更改(提交到源代码管理系统)都要经过一个复杂的过程才能被发布。
Pipeline提供了一组可扩展的工具,通过Pipeline Domain Specific Language(DSL)syntax可以达到Pipeline as Code(Jenkinsfile存储在项目的源代码库)的目的。
Stage:阶段,一个Pipeline可以划分成若干个Stage,每个Stage代表一组操作,例如:“Build”,“Test”,“Deploy”。
注意,Stage是一个逻辑分组的概念,可以跨多个Node
Node:节点,一个Node就是一个Jenkins节点,或者是Master,或者是Agent,是执行Step的具体运行环境。
Step:步骤,Step是最基本的操作单元,小到创建一个目录,大到构建一个Docker镜像,由各类Jenklins Plugin提供,例如:sh ‘make’
Pipeline五大特性
Jenkinsfile 是 Jenkins 2.x 核心特性 Pipeline 的脚本,由Groovy语言实现。Jenkinsfile一般是放在项目根目录,随项目一起受源代码管理软件控制,无需像创建“自由风格”(Jenkins FreeStyle)项目一样,每次可能需要拷贝很多设置到新项目,提供了一些直接的好处:
Pipeline支持:Declarative(在Pipeline 2.5中引入)和Scripted Pipeline两种格式。两者都支持建立Pipeline,两者都可以用于在Web UI中定义一个流水线Jenkinsfile,将Jenkinsfile文件创建并检查到源代码控制库中通常被认为是最佳做法。
(蓝珲的PDF讲稿,选择一些比较重要的内容,可能与其他笔记内容重复;内容是机翻的,理解可能不太通顺)
旧计划很快就会过时。
你有一个计划,但你总是被额外的“请求”而分心。其称为请求蠕变(request creep)的现象。
• 请求将“一些小功能”添加到产品而无需更改预算或时间表。
• 要求接纳一些在职人员在项目之间找到对他们有用的东西去做。
• 减少设计审查范围的请求(在为了弥补一些时间表)。
你应该仔细考虑请求的影响。你应该能够协商计划、时间表的相应变更和预算。
我建议你遵循的步骤。
专有软件(Proprietary Software)
proprietary :与所有者或所有权有关。
该软件归一家公司所有,该公司规定对使用、修改和分发的许多限制。我们需要先付款(显式或隐式)用它。
网景的错误
糟糕的产品,糟糕的产品决策,产品方向。
变得太大了。
停止创新。
功能蠕变。不
断添加“不”的功能休息一下,没有时间重新构建”。
反微软。
粗糙、复杂的代码。
IE 占了上风。
频繁发布
编程基本定律(Joel Spolsky):阅读代码比编写代码更难。
从头开始可能是一种荒谬的策略或行为。
创业公司杀手:建立一个扔掉。
大误解:新代码比旧代码好。
原因:
• 你不能保证新代码比旧代码好。
• 当我们添加代码时,我们添加了功能,也可能带来新的Bug。
• 虽然旧代码看起来很丑,但新代码甚至可以更差。
• 你可能会再次犯旧错误,并犯下新错误错误。
• 旧代码已被使用、测试和修复。新的代码没有。这意味着巨大的努力和时间(通常对您来说是不可见的)已投入旧代码。那就是钱。
• 旧代码:也许修复只是一行代码,或者只是几个字符。但这需要巨大的努力。扔掉代码就是扔掉努力,有时是多年的编程工作。
•(旧代码)不会因为坐下而获得错误在你的硬盘上。- 乔尔·斯波尔斯基。
Software years:即使您的新代码更好,您可能会落后几年,并且因此失去市场。
使用分支避免瓶颈
有利于协同开发。
发布分支,错误修复分支,实验分行等
分支之所以有价值,是因为它们变得稀缺资源——项目代码中的工作室——进入丰富的。
分支做起来成本低。
提出拉取请求、请求审查和合并(当所有审稿人都满意时)。
隔离和稳定释放线到发展线。
自由使用分支。
大多数分支应该合并他们的更改尽快进入主线并消失。
当我们进行合并时,表明这是一个合并到日志消息中
拉取请求(Pull Requests)
拉取请求是来自贡献者的请求,某个变更被“拉”(合并)的项目进入项目。
一旦贡献到达,它通常会消失通过审查和修订过程,包括贡献者与各方面的沟通项目的成员。
代码更改合并到项目的主分支是什么时候正式成为项目的一部分。
对项目的99.9%的贡献应该通过拉取请求 - 审查 - 修订 - 合并的过程。
拉取请求应该有一个目的。如果你有很多目的,那就创造很多分支并发出许多拉取请求。
为什么?
更容易参考一个小项目,更容易审查一个小项目。
基本 Git 命令
git branch
git checkout -b FIX-README
git add .
git commit -m ”README.md: Why, What, How?”
git pull origin master
git push origin FIX-README
git checkout FIX-README
你在项目开源后宣布。
你应该期待什么:
- 影响不大。保持 1.0 安静。
- 一些随意的询问。
- 您的邮件列表中还有几个人。
发布即播种。
形成指数通信网络。
项目→社区
版本(修订)控制系统
Version (revision) Control System
版本控制的核心是变更管理:
谁在哪个日期进行了哪些更改。
两种方式:
commit - 对项目进行更改。
push - 发布对公开在线的提交存储库。
pull (or update) - 拉其他人的更改(提交)您的项目副本中。
commit message - 评论附加到每个提交,描述性质和提交的目的。
repository - 存储更改的数据库并从中发布它们。
clone - 获得自己的开发库通过制作项目中央存储库的副本。
checkout - 切换到分支
revision or commit - 修订或提交
diff - 更改的文本表示。
tag or snapshot - 标签或快照
branch - 项目的副本,受版本控制但被隔离,以便对分支所做的更改不会
影响项目的其他分支。一个好方法拥有多条独立的发展路线。“主线”、“主干”、“主线”、“发布分支”
merge - 将更改从一个分支移动到其他分支。
conflict - - 当两个人试图做出不同的更改到代码中的相同位置。“解决”问题冲突。
revert - 撤消已提交的软件更改。
失去焦点(Losing Focus)
甚至不要考虑创建膨胀软件,或者群件。
继续您的产品愿景。
许多干扰,一路向北
发布节奏(Rhythm of Releases)
过于频繁的发布被认为不是成熟产品所必需的
梅特卡夫定律(Metcalfe’s Law)
网络的价值随着网络规模的平方而增长。
The value of a network grows by the square of the size of the network
德尔福效应(Delphi Effect)
集成方法
一大批同样专业的观察家的平均意见比一个随机选择的观察家的意见更可靠
专家的差异很重要
首先寻找现有的解决方案
Looking for Existing Solutions First
也许不值得重新发明轮子。相反,向现有功能添加一些功能。
例外:出于教育目的,非常专门的应用程序,用于国家安全
不要让任务压倒你。
No Need to Provide Everything At Once
这样做会非常耗时:
• 详尽的设计文档
• 完整的用户手册
• 精美且可移植的打包代码
• 平台独立
Hacktivationenergy
一个新人必须投入的精力,在他开始找回一些灵感(手感)之前
摩擦(Friction)
潜在贡献者成为真正贡献者所需的能量
Alpha - 第一个版本,有已知错误。
Beta - 修复了严重的已知错误,请用户提供详细的反馈
10-year Rule. Good Software Takes Ten Years. Get Used To it. Sustained effort is needed.
避免私下讨论(Avoid Private Discussions)
与公开讨论一样缓慢和繁琐是的,从长远来看,它几乎总是可取的。如果没有理由将其设为私有,则应该公开。
为什么?
对粗鲁行为的零容忍政策
在分布式工作环境中,写下所有内容对于有效沟通至关重要
代码审查(Code review)
提交审查。
开源世界中的同行评审。
好处:
为什么我们专注于审查最近的变化?
• 它在社交方面效果更好。及时反馈新鲜变化。与人互动的好方法。确认他们所做的事情很重要(被看到并明白了)。人们在做他们最好的工作时知道其他人会花时间对其进行评估
• 最近的变化是获得熟悉代码库。也看看受影响的呼叫者和被呼叫者。
审查应该是公开的,以便其他人可以看到它并知道发生了审查,并且是期待。
提交通知很有用
技术债(Technical debt)
“当走捷径并交付不适合当前编程任务的代码时,开发团队会招致技术债务。这种债务降低了生产力。生产力的损失是技术债务的利益。”
高技术债务会使软件不可维护
自述文件(README)
“In the open”意味着以下事情是公开访问:
- 代码库
- 错误跟踪器
- 设计文件
- 用户文档
- 维基
- 开发者论坛
您的日常工作对公众可见。兼容的开源
“In the open”不一定意味着以下内容
- 允许陌生人将代码检查到您的存储库
- 允许任何人在您的跟踪器中提交错误报告
- 阅读并响应提交的每个错误报告,即使您确实允许陌生人提交
- 回答人们在论坛中提出的每个问题
- 审查发布的每个补丁或建议,何时这样做可能会花费宝贵的开发时间
你的源代码是开放的,但你的时间没有开放
项目需要什么
罐头托管(Canned Hosting)
提供在线协作的在线服务运行自由软件项目所需的工具
优点:
(1)服务器容量和带宽
(2)简单。
缺点:定制有限,无精打细算粒度控制
匿名和参与(Anonymity and involvement)
您不希望陌生人将更改推入您的回购,即使他们被审查。
你不想要一个不方便的参与吧防止快速评论和简单的错误报告。
确保只读操作、错误归档(使用适当的允许使用反垃圾邮件技术,例如验证码)对于匿名、未登录的访问者有用
可浏览性(Browsability)
项目的存储库应该可以在Web上浏览
可浏览性很重要,因为它是一个轻量级的项目数据的门户。
可浏览性还意味着用于查看的规范 URL一个特殊的变化——在讨论过程中没有歧义
票证生命周期(Ticket life cycle)
存储库树中引入的每行代码都必须经过严格的审查过程。这保证了代码基础的整体质量
其他人阅读票证,添加评论,然后也许要求原始申报人澄清一些点
该错误被重现。
该错误得到诊断。分配所有权。放优先事项。
票被安排解决。
该错误得到修复。票已关闭。
需要注意的事情:是不是真正的错误;是否有重复的漏洞。
分叉和可分叉性(Fork and Forkability)
复制一份源代码并用它开始一个竞争项目,称为分叉。
结果:自由软件中没有真正的独裁者项目。
错误的决定最终会引发反抗和分叉。
硬分叉:不向前兼容的分叉
分叉的可能性。
实际分叉
仁慈的独裁者(Benevolent Dictators)
做出最终决定的人。
个性和经验。
不愿做出决定:在大多数情况下,推迟给领域专家或区域维护者。让其他人讨论。
BD - 社区认可的仲裁员。例如,一个项目的创始人。
需要注意的两点:
好BD的特征。
如果项目有一个明显的、好的候选BD,那就是要走的路。否则,请使用民主
懒惰的共识
隐含的共识。
沉默意味着同意。
沉默意味着没有异议
Lazy Consensus
Implicit consensus.
Silence means consent.
Silence means no objection.
版本控制意味着您可以放松
Version control means you can relax
更改可以恢复。
所以我们可以消除坏的或仓促的影响判断。
但这并不意味着我们可以滥用回归
阿帕奇方式(The Apache Way)
基于共识、社区驱动的治理。
项目管理委员会具有较高的自由度。
使用邮件列表进行通信(异步)。语音交流非常稀有的。为什么?
做决定:“meritocracy”, “do-ocracy”
做事者的力量:做的越多,允许做的越多。使用惰性共识(沉默意味着没有异议)。+1, 0 (没有意见), -1 (需要提供另一种建议)。
ASF Incubator
成为 ASF 项目的切入点。
它根据成功可能性过滤项目。
要求:工作代码库,意图转让足够的知识产权,以及赞助 ASF 成员或官员
邮件列表(Mailing lists)
使用邮件列表而不是私人邮件列表的好处通信是一种共享资源,其中其他人也可以从常见的错误中学习社区,我们共同成长。
审查然后提交或提交然后审查(Review-Then-Commit or Commit-Then-Review)
RTC:改变首先需要共识批准。
CTR:随意更改,有可能被追溯否决
未能提供高质量的批评可能是一种侮辱
你必须对一切做出回应。
沉默也是交流。如果你不知道如何回答,用沉默回答
显着使用档案(Conspicuous use of archives)
开源项目中的所有通信都是存档。
为什么档案很重要?
他们提供了一个基础供讨论。
在提问之前先搜索存档。
为了避免重复,如果一个问题已经在档案中回答,参考它(例如,包括一个链接到存档页面)
选择合适的论坛
IRC 或开发邮件列表?
IRC:适合快速响应,不适合制作由于样本量很小,因此做出了重大决定。
邮件列表:更正式。每一个感兴趣的人将有机会看到并回应相关帖子,不分时区,时间表。
发布分支(Release branch)
发布分支只是版本中的一个分支控制系统(见分支),其上的代码用于此版本的可以与主线隔离发展。
混沌之力(Forces of Chaos)
一位重要的开发人员突然失去了兴趣
长期雇用一个真正有经验的程序员
在项目中至少呆了几年。
拥有良好的声誉。
有影响。
非常了解代码。
了解有关设计决策的旧讨论。
具有提交访问权限。
如何培养新人?
从错误修正和清理任务开始,这样他就可以学习代码库并让自己了解社区。
有经验的程序员应该阅读所有内容新人发布(例如,错误修复补丁)并成为可以回答他的问题。
评估开源项目(Evaluating Open Source Projects)
社会健康和项目成熟度。Social health and project maturity.
他们的开发者有多庞大和多样化社区?
他们是否定期获得新的贡献者?
他们是否处理传入的错误报告合理的方式?
他们是否足够频繁地发布稳定版本您的需求?
tips:
首先查看错误跟踪器活动。
衡量提交多样性,而不是提交率。
评估组织多样性。
讨论论坛。
新闻、公告和发布
测试金字塔
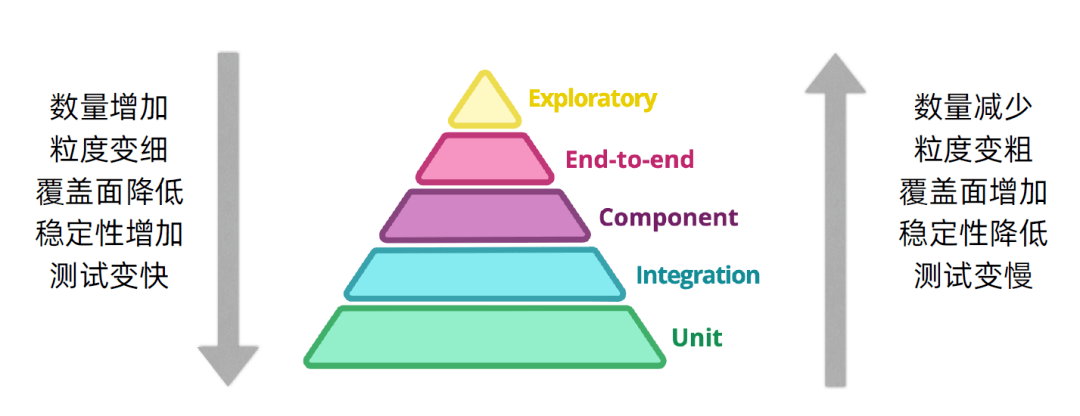
(1) 尽可能地多做 单元测试 和 集成测试,因为他们的执行速度相较于上层的几个测试类型来说快很多且相对稳定,可以一天多次执行。一般来说,我们都会将单元测试 和 集成测试 做到持续集成构建任务中去,比如放到Jenkins中每天定时执行1~2次,或者每次push代码到git仓库后执行,总之,就是要确保可以频繁执行以确保代码质量。
(2) 尽可能地少做 组件测试、端到端测试 和 探索性测试,因为他们的执行速度相较单元测试 和 集成测试 会慢很多,且不够稳定,无法做到一天多次执行,每次执行都要等很久才能获得反馈结果。但是,他们的覆盖面比下层的单元测试和集成测试要广一些。总之,就是要确保一定周期内或者关键节点时间执行以下这几个测试以确保软件质量。
古德哈特定律(Goodhart’s law),是以 Charles Goodhart 的名字命名的,这是一个非常有名的定理:当一个政策变成目标,它将不再是一个好的政策。
当衡量标准成为目标时,它就不再是一个好的衡量标准
Goodhart软件开发定律的一个例子是代码行数。代码行数提供了一种衡量软件产品大小的方法。但是,当用作目标时,代码的质量会下降。
应该根据软件本身的结构进行精炼或分离,而不是一个混乱的意大利面条式代码。
Chapter 6. Communications (producingoss.com)
清晰写作的能力也许是在开源环境中最重要的技能。从长远来看,它比编程人才更重要。
You Are What You Write (producingoss.com)
结构和格式
不要像编写手机短信那样编写所有的东西。要使用完整的句子,每个句子首字母要大写,也要根据需要分段。在编写电子邮件和其他内容时这一点最重要。邮件、文档、bug报告和其他会永久保存的东西,必须使用标准语法和拼写,并有一致的叙事结构。
对于个别的电子邮件,有经验的开源开发者会使用特定的约定:
内容
基调(语气,风格)
通过仔细注意人们行为的长期模式,即使你从未面对面地遇到他们,你也会开始意识到他们是个体。通过对自己写作的语气敏感,你可以对别人的感受产生惊人的影响,从而最终受益。
识别无礼
面容
Avoiding Common Pitfalls (producingoss.com)
不要发表无目的的文章
三类信息占据:
生产性与非生产性线程
非生产性线程的一些特征:
主题越小,辩论时间越长
对于长期的主题,讨论的数量与主题的复杂度成反比的原理,被非正式的称为Bikeshed效应(BSD)
避免圣战
圣战的一个共同特点是,在继续讨论能否解决争端这一问题上存在分歧。
处理圣战:
第一个答案是,做好准备避免其发生
当圣战不可避免时,尽早决定你要关注多少,并乐意公开放弃。当你这样做,你可以说你正在退出,这场圣战毫无价值,而不要展示出挖苦,并且不要利用这个机会对对方的辩论做最后一次攻击。只有优雅的去做才能有效的放弃。
“嘈杂的少数派”效应 noisy-minority
在任何邮件列表讨论中,少数人很容易给人留下非常不同的印象,因为列表中充斥着大量冗长的电子邮件。
对付这种影响的最佳方法是非常清楚地指出这一影响,并提供佐证,表明与同意者相比,实际持不同政见者人数是多么少。
不要抨击竞争的开源产品
避免对竞争的开源软件发表负面意见。给出负面事实是完全可以的——即很容易在良好的比较图表中看到的那种可以证实的断言。但是,出于两个原因,最好避免对性质不那么严格的负面描述。首先,他们容易发动有损于富有成效的讨论的火焰战。其次,更重要的是,您项目中的一些开发人员也可能参与竞争项目,或者来自其他项目的开发人员可能正在考虑为您的项目做出贡献。
Testing and Releasing (producingoss.com)
软件公开之前,它应该经过一些最低数量的开发人员(通常是三个或更多)的测试和批准。然后,必须使用数字签名和识别哈希向全世界发出批准信号。
签名和哈希的目的是给用户一种方法来验证他们收到的副本没有被恶意篡改。
获得开发人员批准不仅仅是他们检查发布是否存在明显缺陷的问题。
候选版本
对于包含许多变更的发布版本,许多项目会首先推出发布候选版本
在大多数其他方面,候选发布一定要与正式发布保持相同的待遇。alpha、beta或rc修饰足以警告保守的用户等待真正的发布,而候选发布的声明邮件也必须指出他们的目的是征求反馈。除此以外,应该对候选发布提供与正式发布相同的关注。毕竟,你希望人们使用候选版本,因为暴露是发现bug的最佳方法,而且也因为你永远无法获知哪个候选会最终成为正式版本。
宣布发布
每当你提供下载发布tarball的URL时,一定要确保给出MD5/SHA校验和数字签名文件的链接。
在宣告邮件和新闻页中,不应该仅仅报告关于发布的宣传信息,而应该包含CHANGES文件中相关的部分,这样人们就能够看到自己是否有兴趣去升级。
最后,不要忘记感谢项目团队、测试人员以及所有花时间发起bug报告的人。
TeamCollaborationTutorial/team.rst at master · spm2020spring/TeamCollaborationTutorial (github.com)
集中式工作流保留了在 SVN 下的工作风格,对于每一个 Repo,集中式工作流只使用 master 分支进行开发。
从 master 克隆分支到本地
git clone https://github.com/spm2020spring/TeamCollaborationTutorial.git
(只能克隆一次)
去工作目录
cd TeamCollaborationTutorial
获取当前分支
git branch
创建并切换分支(Copy the whole castle to make castle2)
git checkout -b castle2
(现在 castle2 包含了主分支的所有内容。此命令只能执行一次。当您希望切换到 castle2 时,使用上面的命令而不使用 -b)
现在在 castle2 分支
编辑文件、暂存和提交
git add .
git commit -m “file changed: specific messages (what & why)”
(一切发生在 castle2 ,原来的不受影响)
切换回主分支 master
git branch master
现在在castle2中所做的更改合并到master中
git merge castle2
中央仓库(central repo)发生了什么?
当我在 castle2 内部努力工作时,我团队中的其他人可能已经更新了中央仓库
与更新同步
git pull origin master
将 master 分支推送到 origin 服务器
git push origin master
功能分支工作流背后的核心思路是所有的功能开发应该在一个专门的分支,而不是在master分支上。
这个隔离可以方便多个开发者在各自的功能上开发而不会弄乱主干代码。另外,也保证了master分支的代码一定不会是有问题的,极大有利于集成环境。
从 master 克隆分支到本地
git clone https://github.com/spm2020spring/TeamCollaborationTutorial.git
(只能克隆一次)
去工作目录
cd TeamCollaborationTutorial
获取当前分支
git branch
创建并切换分支(Copy the whole castle to make castle2)
git checkout -b chinese-castle
(现在 chinese-castle 包含了主分支的所有内容。此命令只能执行一次。当您希望切换到 chinese-castle 时,使用上面的命令而不使用 -b)
现在在 chinese-castle 分支
所有与此功能相关的更改(或错误修复)都必须发生在 chinese castle 中。
编辑文件、暂存和提交;
git add .
git commit -m “file changed: specific messages (what & why)”
更新分支 chinese-castle
git pull origin master
将 chinese-castle 推送到中央仓库
git push origin chinese-castle
Detailed, dispassionate technical criticism can be regarded as a kind of praise.
详细、公正的技术批评可以视为赞美
应该是对的
At the Apache Software Foundation (ASF), Project Management Committees (PMCs)
can manage their projects independently and set per-project policies, as long as they follow the
Apache corporate policies in terms of licensing, branding, infrastructure and so on.
在 Apache 软件基金会 (ASF),项目管理委员会 (PMC) 可以独立管理他们的项目并设置每个项目的政策,只要他们遵循 Apache 公司在许可、品牌、基础设施等方面的政策。
应该是对的
Let code to comment ratio, φ, be the amount of code divided by the amount of comments.
A reasonable value of φ ranges from 3 to 10, according to the top 10 software listed at OpenHub.
让代码与评论的比率 φ 是代码量除以评论量。 根据 OpenHub 列出的前 10 名软件,φ 的合理值范围为 3 到 10。
对
When preparing a release, it is a good practice to create a release branch, isolated from
the mainline development.
在准备发布时,最好创建一个发布分支,与主分支隔离。
应该是对的
Reviewing changes before merging them to the master branch is a waste of time
在将更改合并到 master 分支之前审查更改是浪费时间
应该是错的
Open source software can be used for commercial purposes
开源软件可用于商业用途
应该是对的
Your priority as the manager of a software team is building the development abstraction
layer on which programmers can produce.
作为软件团队经理,您的首要任务是构建程序员可以在其上进行生产的抽象层。
应该是对的(见 Reading 3)
You developed a Web application and want to open source it. Affero GPL is a better choice of license than GPL because it has an extra clause designed specifically for online applications.
您开发了一个 Web 应用程序并希望将其开源。 Affero GPL 比 GPL 更好许可,因为它有一个专门为在线应用程序设计的额外条款。
应该是对的(其主要针对的是基于web的应用程序,要求网络程序开发者必须让源代码能通过网络分发)
Having many bug reports in your bug tracking system indicates that your software project is unlikely to be successful. Therefore, a good project manager does not use a bug tracker.
在您的错误跟踪系统中有许多错误报告表明您的软件 项目不太可能成功。 因此,优秀的项目经理不会使用错误跟踪器。
显然是错的
Don’t hire a tester. Ask the programmer to do testing, because you can save money spent on salary and the programmer knows the program better.
不要聘请测试人员。 请程序员做测试,因为可以省钱花在薪水上,程序员更了解程序。
错(开发和测试是软件生命周期的不同组成部分,专门的测试人员更能保证软件的高质量。)
Describe fork. Describe feature creep.
描述 fork(分支).描述 feature creep(功能蔓延).
1 | 答案: |
分支:从一个软件包拷贝了一份源代码然后在其上进行独立的开发,创建不同的软件。这个术语不只意味着版本控制上的分支,同时也意味着开发者社区的分割,是一种形式的分裂。
功能蔓延(feature creep),有时也被称为需求蔓延(requirements creep)或范围蔓延(scope creep),它是指在发展过程中产品或设计的需求增加大大超过他们原来预期的趋势,导致其功能不是原本计划的并且要承担产品质量或生产进度的风险。
In terms of treating old code, Joel Spolsky suggested “ ___ old code”.Please fill in the line. What are the good things about old code
在处理旧代码方面,Joel Spolsky 提出了“___旧代码”。 请填写行。 旧代码有什么好处
1 | 答案: |
What does do-ocracy mean in The Apache Way?
Apache Way 中的 do-ocracy 是什么意思?
1 | 答案: |
抛开纯粹的被动反应,事情的实际发展方向通常是由开发者的工作来决定,而不是由任何宏伟的计划决定。如果你干了具体的活,那么实际上是你控制事情的发展方向。如果您需要某些东西,那就去实现它。这种方式偶尔用笨拙的英语-希腊语混合词 “ do-ocracy ” (“干活者掌权”——译者注)来描述。我将其称为 “ Pratocracy ”,即“创客法则”。它既适用于 Apache 核心团队,也适用于更广泛的社区。
(应该不考)
What does WIP mean in Kanban? Why is it important to have a WIP limit?
WIP 在看板中是什么意思? 为什么设置 WIP 限制很重要?
1 | 答案: |
在敏捷开发中,WIP限制决定了每种情况下的工作流中可以存续的最大工作量。限制进行中的工作数量可以更容易辨识团队工作流中的无效工作。在情况变得更糟前,一个团队的持续交付通道中的瓶颈是非常容易辨别的。
WIP限制通过强制让团队聚焦在更小的一套任务中来改善吞吐量和减少“将要完成”的工作量。从根本上来讲,WIP限制鼓励的是“完成”的文化。更重要的是,WIP限制让阻碍和瓶颈显而易见。当有明确指示现有工作遇到瓶颈时,团队可以聚焦在阻塞问题上尽快的理解、实施和解决。一旦消除阻塞,团队中的工作将再次开始流动。这些优势可以确保在最短的时间内向用户交付有价值的增量,从而使得WIP限制成为敏捷开发中一个非常有价值的工具。
Given the following releases of software, LRR 1.0, LRR 0.9, LRR 0.9 Alpha, LRR 0.9 Beta. Order them by time (oldest first).
鉴于以下软件版本,LRR 1.0、LRR 0.9、LRR 0.9 Alpha、LRR 0.9 测试版。 按时间排序(最老的在前)。
1 | 答案: |
LRR 0.9 Alpha -> LRR 0.9 Beta -> LRR 0.9 -> LRR 1.0
Alpha:预览版,或者叫内部测试版;一般不向外部发布,会有很多 Bug;一般只有测试人员使用。
Beta:测试版,或者叫公开测试版;这个阶段的版本会一直加入新的功能;在 Alpha 版之后推出。
RC(Release Candidate):最终测试版本;可能成为最终产品的候选版本,如果未出现问题则可发布成为正式版本
多数开源软件会推出两个RC版本,最后的 RC2 则成为正式版本。
Feature-branching workflow and Pull Request. You are going to manage the online web application, Lab Report Repository (LRR). The central, remote project repo of LRR is hosted at https://github.com/lanlab-org/LRR.git.
功能分支工作流和拉取请求。 您将管理在线 Web 应用程序——实验室报告存储库 (LRR)。 LRR 的中央远程项目存储库托管在 https://github.com/lanlab-org/LRR.git。
You are asked to add a new feature X to LRR and use the feature-branching workflow, please describe each step. Make sure that you also include git commands.
您被要求向 LRR 添加新功能 X 并使用功能分支工作流程, 请描述每个步骤。 确保您还包含 git 命令。
1 | 答案: |
What is the main purpose of Pull Request?
拉取请求的主要目的是什么?
1 | 答案: |
“拉取请求”是一种机制,用于表示一个分支的更改已准备好合并到另一个分支中。 它们为利益干系人提供了审查和讨论提议的更改的机会,以确保基础分支中的代码质量尽可能地保持最高。
What should you do if you see a comment from other people in your Pull Request?
如果您在 Pull Request 中看到其他人的评论,您应该怎么做?
1 | 答案: |
尽快回复并解决。
What is the most important message the following figure conveys? How could reviews in Pull Request help improve software’s internal quality?
下图传达的最重要的信息是什么? Pull Request 中的评论如何帮助提高软件的内部质量?
1 | 答案: |
Automated regression testing. As a software project manager, you want to ensure that your team’s new changes to software do not break existing functionalities, so you ask your team to run regression testing for every non-trivial change they made. If breakage occurs, you get a regression. Here is an example of regression: adding a new, working feature makes several old features stop working.
自动化回归测试。 作为软件项目经理,您希望确保 您的团队对软件的新更改不会破坏现有功能,因此您要求您的团队运行 对他们所做的每个重要更改进行回归测试。 如果发生破损,您将得到回归。 这里 是回归的一个例子:添加一个新的、有效的功能会使几个旧的功能停止工作。
Why is automated regression testing important? Answer this question in terms of the consequences of not having automated regression testing.
为什么自动化回归测试很重要? 回答没有自动回归测试的后果。
1 | 答案: |
自动回归测试将大幅降低系统测试、维护升级等阶段的成本。
In which scenarios do you expect to get most from automated regression testing? Give one scenario.
您希望在哪些场景中从自动化回归测试中获得最大收益? 给出一个场景。
1 | 答案: |
The following table compares the time required to run manual testing and the time required to run automated testing. After how many repeated testing on the Post new assignment functionality will you see overall time saving by using automated testing instead of manual testing? Please give a number. Briefly describe how you derived this number. Note: you can assume that manual testing needs zero extra preparation time, while automated testing requires us to prepare a testing script first. Overall time saving is achieved when the accumulative time spent by using the automated solution is less than the accumulative time spent by using the manual solution.
下表比较了手动测试所需的时间和自动化测试所需的时间。 在对 Post new assignment 功能进行多少次重复测试后,您会看到使用自动化测试而不是手动测试节省了总体时间吗? 请给出一个数字。 简要描述你是如何得出这个数字的。 注意:您可以假设手动测试需要零额外的准备时间,而自动化测试需要我们先准备一个测试脚本。 当使用自动化解决方案花费的累计时间小于使用手动解决方案花费的累计时间时,可以实现总体时间节省。
| LRR functionality | Manual | Automated | Time spent on writing the automated testing script |
|---|---|---|---|
| Sign in | 37 secs | 13 secs | 26 mins |
| Post new assignment | 59 secs | 24 secs | 14 mins |
1 | 答案: |
A license provides protection to software. A software license is usually issued by the government.
许可证为软件提供保护。 软件许可证通常由政府提供。
错(软件许可是软件发布者和最终用户之间的协议合同)
The Project Management Committees (PMCs) at the Apache Software Foundation (ASF) have great autonomy when setting per-project policy.
Apache 软件基金会 (ASF) 的项目管理委员会 (PMC) 在设置每个项目的政策时有很大的自主权。
对
A bug tracker tracks bugs only. Don’t add feature requests to a bug tracker. They will pollute it.
错误跟踪器仅跟踪错误。 不要向错误跟踪器添加功能请求。 他们会污染它。
错
A project manager needs the sharpest programming skills.
项目经理需要最敏锐的编程技能。
错
Praise and criticism can be diluted by inflation. Detailed, dispassionate criticism is often taken as a kind of praise. Most people respond pretty well to technical criticism that is specific, detailed, and contains a clear (even if unspoken) expectation of improvement.
赞美和批评可以被通货膨胀冲淡。 详细的、冷静的批评往往是 作为一种赞美。 大多数人对具体的技术批评反应很好, 详细,并包含明确的(即使是不言而喻的)改进期望。
对
Benevolent Dictatorship (BD) won’t work well as a means of governance in open source projects. Consensus-based democracy is preferred.
慈善独裁者(BD)在开源中不能很好地作为一种治理手段项目。 以共识为基础的民主是首选。
错
Meritocracy is a key part of The Apache Way. One has to contribute substantially to the project in order to become a committer (who has write access to the master copy of the source code).
Meritocracy 是 The Apache Way 的关键部分。 一个人为了成为提交者(谁对源的主副本有写访问权限代码),必须要做出重大贡献项目
对(在Apache社区中谁有能力做这个事情,谁就去这个事情)
Opening a formerly closed project is an easy task.
打开以前关闭的项目是一项简单的任务。
错
Having many bug reports in your bug tracking system indicates that your software project is unlikely going to be successful.
在您的错误跟踪系统中有许多错误报告表明您的软件项目 不太可能成功。
错
Bug tracking enables developers to plan releases.
错误跟踪使开发人员能够计划发布。
对
Technical debt. What is a technical debt? What is consequence of accumulating too many such debts?
**技术负债。 什么是技术负债? 积累太多这样的债务会有什么后果? **
1 | 答案: |
技术负债指开发人员为了加速软件开发,在应该采用最佳方案时进行了妥协,改用了短期内能加速软件开发的方案,从而在未来给自己带来的额外开发负担。这种技术上的选择,就像一笔债务一样,虽然眼前看起来可以得到好处,但必须在未来偿还。软件工程师必须付出额外的时间和精力持续修复之前的妥协所造成的问题及副作用,或是进行重构,把架构改善为最佳实现方式。
Project parasites. What are the main characteristics of project parasites?
**项目寄生虫。 项目寄生虫的主要特征是什么? **
1 | 答案: |
Code review. Code review enables us to improve software quality and enhance interaction with other developers. When we review code, why should we focus on reviewing recent changes?
代码审查。 代码审查使我们能够提高软件质量并增强与其他开发人员的互动。 当我们审查代码时,为什么要专注于审查最近的更改?
1 | 答案: |
Voting to move on. The ASF has a bit weired voting and veto process. When one votes -1, what does he want to express, and what other information must he provide?
投票继续前进。 ASX 的投票和否决程序有点奇怪。 当投票-1,他想表达什么,他还必须提供什么信息?
1 | 答案: |
Community-driven project management. “We worry about any community which centers around a few individuals who are working virtually uncontested.” Why does the ASF worry about the formation of uncontested individuals
社区驱动的项目管理。 “我们担心任何以几个几乎毫无争议地工作的人为中心的社区。” 为什么ASF担心无争议个体的形成
1 | 答案: |
Version control. Describe the purpose of the push command while interacting with github
版本控制。 描述当与 github交互时,推送命令的目的
1 | 答案: |
Hacktivation energy. What is hacktivation energy for newcomers to a project?
黑客化能量。 什么是项目新人的黑客化能量?
1 | 答案: |
License. How to apply a license to your software application?
许可证。 如何将许可证应用于您的软件应用程序?
1 | 答案: |
Looking for alternatives first. Why is it important to look at alternatives before we start a project?
首先寻找替代品。 为什么在我们开始一个项目之前考虑替代方案很重要?
1 | 答案 |
Noisy minority. What is the “Noisy Minority” effect? How to handle this effect?
喧闹的少数派。 什么是“嘈杂的少数派”效应? 如何处理这种影响?
1 | 答案: |
Mailing lists for public communication. Read the following notice from the Apache Hadoop Project PMC and answer the following questions. “We ask that you please do not send us emails privately asking for support. We are non-paid volunteers who help out with the project and we do not necessarily have the time or energy to help people on an individual basis. Instead, we have setup mailing lists …” What are the benefits of using mailing lists for open source projects? In particular, compare mailing lists with QQ/WeChat as a means of technical communication.
用于公共通信的邮件列表。 阅读来自 Apache Hadoop 项目 PMC 的以下通知并回答以下问题。 “我们要求您不要私下向我们发送电子邮件寻求支持。 我们是帮助项目的无偿志愿者,我们不一定有时间或精力单独帮助人们。 相反,我们设置了邮件列表……”使用邮件列表进行开源项目有什么好处? 特别是将邮件列表与QQ/微信作为技术交流的方式进行比较。
1 | 答案: |
Release criteria. Johanna Rothman proposes in his 1998 article Of Crazy Numbers and Release Criteria to use the magic number 36 as a release criterion. That is, enter all software bugs into our bug tracking system, if there are less than 36 high-priority bugs, then we could release a beta version, and if we have closed all open high-priority bugs, then we could release an official version. Why does this approach make sense? Does the number has to be 36?
发布标准。 Johanna Rothman 在他 1998 年的文章 Of Crazy Numbers and Release Criteria 中提议使用幻数 36 作为发布标准。 也就是把所有的软件bug输入到我们的bug追踪系统中,如果高优先级bug少于36个,那么我们可以发布一个测试版,如果我们已经关闭了所有开放的高优先级bug,那么我们可以发布一个正式版本。 为什么这种方法有意义? 数字必须是36吗?
1 | 答案: |
One commit, one change. Each git commit should be small and atomic
一次提交,一次更改。 每个 git commit 都应该是小而原子化的
Benno Schulenberg, the current maintainer of the GNU nano editor, seems to follow the “one commit, one change” principle. Below is one of his recent commits to the GNU nano source code repository. What change did he make in this commit, and for what purpose? Does this change satisfy the small and atomic criteria?
GNU nano 编辑器的当前维护者 Benno Schulenberg 似乎遵循“一次提交,一次更改”的原则。 下面是他最近对 GNU nano 源代码库的提交之一。 他在这次提交中做了什么改变,目的是什么? 这种变化是否满足小和原子标准?
1 | author Benno Schulenberg <bensberg@telfort.nl> 2019-06-12 09:46:19 +0200 |
1 | 答案: |
In practice, though, I frequently saw big and entangled changes per comit. Below are two shortened examples from the commit history made by the students from my Software Project Management class:
然而,在实践中,我经常看到每次提交都会发生大而复杂的变化。 以下是我的软件项目管理课程的学生制作的提交历史记录中的两个简短示例:
1 | gymgym1212 committed on Apr 22 |
How many files were affected by M-michael-zhang’s commit on April 15? Why did that happen? What are the risks of having too many changes per commit?
M-michael-zhang 4 月 15 日的提交影响了多少文件? 为什么会这样? 每次提交有太多更改的风险是什么?
1 | 答案: |
Bug reports and fixes.
Developers rely on good bug tracking for their daily efforts on improving software quality. Also, project observers, who can be potential participants or supporters, would not take a project seriously if it dose not have a publicly-accessible bug database. Being able to read, analyze and respond to bug reports is crucial for a project’s success. Read the following bug report, bug discussion and bug fix. Answer the following questions. Hint: read the questions in the last page first.
错误报告和修复。
开发人员依靠良好的错误跟踪来提高软件质量。 还有项目观察员,可以是潜在的参与者或支持者,如果项目没有可公开访问的错误数据库,则不会认真对待该项目 。 能够阅读、分析和响应错误报告对于项目的成功至关重要。 阅读遵循错误报告、错误讨论和错误修复。 回答以下的问题。 提示:阅读首先是最后一页的问题。
1 | bug #56023: savefile (^S) says "[Cancelled]" in nano-4.0 on an ARM |
1 | author Devin Hussey <husseydevin@gmail.com> 2019-03-28 17:28:47 -0400 |
Who is the original bug reporter?
谁是最初的错误报告者?
What bug did he report, and for which version of nano?
他报告了什么错误,以及哪个版本的 nano?
How long did it take him to submit a patch after he reported the bug?
他在报告错误后花了多长时间提交补丁?
Who applied the patch to the nano source code repository for the next release? From the commit record, what is his role in the nano project?
谁在下一个版本的 nano 源代码库中应用了补丁? 从提交记录看,他在nano项目中的作用是什么?
How many people have participated in discussing this bug?
有多少人参与了这个bug的讨论?
What are the advantages of using a bug tracker over using email for reporting and recording bugs?
与使用电子邮件报告和记录错误相比,使用错误跟踪器有哪些优势?
1 | 答案: |
设计一个简单的在线考试系统
老师上传一个测验和考试学生列表。测验的格式是纯文本,主题题可附答案,主观题可附参考答案。系统将测验做出网页的格式,方便学生替换,填写。
老师可以批改每次测验每个同学的试卷。答题结果如果是主题题,则自动改分,如果是主观题,则老师手动改分。
老师可以下载每次测验所有同学的成绩。
学生可以登录答题(只有在学生列表中的学生才能答题)。
学生可以看到每次测验自己的分数以及做题详情。
在线考试系统的角色主要分两类:学生和老师。
学生的功能基本操作有:登录、在线考试、在考试后一段时间查看分数及对应题目的解析、修改个人信息。
学生功能模块有:学生主模块、考试模块、登录模块、个人信息模块
1 | //学生主模块 |
老师的基本操作有对学生信息、试卷信息、学生考试、老师信息等进行相应的增删改查工作。
老师功能模块有:老师主模块、学生信息管理模块、考试信息管理模块、试卷信息管理模块、老师用户信息模块
1 | //老师主模块 |